Paperless-ngx meets local AI: Ein komplett autonomer Workflow (Das große V2 Update)
Hallo zusammen! Ich möchte heute meinen Workflow teilen, mit dem ich meine Paperless-ngx Instanz um ein komplett lokales, autonomes KI-Backend (auf Basis von Ollama) erweitert habe. Das Setup ist in den letzten Tagen durch wertvolles Feedback massiv gewachsen und hat nun den Status „Rock Solid“ erreicht: Echte asynchrone Parallelverarbeitung, absolute Absturzsicherheit und unantastbare PDF/A-Originaldokumente.
Das Ziel: Keine externen Cloud-Abhängigkeiten (Datenschutz!), maximale Hardware-Effizienz und perfekte Erkennungsrate (selbst bei schlechten Handy-Fotos oder zerkratzten Ausweiskopien).
 Hardware & Systemvoraussetzungen
Hardware & Systemvoraussetzungen
Mein System läuft auf Windows 11 Pro mit WSL2 (Ubuntu 24.04). Die Hardware-Basis bildet ein Intel Core i7 Ultra mit 32 GB DDR5-RAM und einer Nvidia RTX 5060 Ti (16 GB VRAM). Die 16 GB VRAM der Grafikkarte sind der absolute Sweet-Spot, um die Qwen-Modelle mitsamt der Embedding-Datenbank performant im Grafikspeicher zu halten.
 Architektur & Setup (Hybrid-LLM Ansatz)
Architektur & Setup (Hybrid-LLM Ansatz)
Das Setup läuft vollständig via docker-compose. Das Herzstück ist ein selbst geschriebener, radikal entkoppelter ai_watchdog Container (Python). Um Hardware-Ressourcen zu schonen und gleichzeitig extrem schnell zu sein, setzt das System auf einen Hybrid-Zweiklang bei den lokalen LLMs (gesteuert von Ollama):
-
Das schwere Vision-Modell (qwen2.5vl:7b): Hat „Augen“, liest Bilder, ignoriert Hologramme auf Ausweisen und extrahiert komplexe Metadaten aus dem Layout.
-
Das leichte Text-Modell (qwen2.5:3b): Ist rasend schnell, braucht kaum VRAM und liest gigantische Textblöcke fehlerfrei (ideal für Zusammenfassungen).
-
Das Embedding-Modell (nomic-embed-text): Für die blitzschnelle semantische Vektorsuche (Speicherung in ChromaDB).
 Der Workflow (Schritt für Schritt)
Der Workflow (Schritt für Schritt)
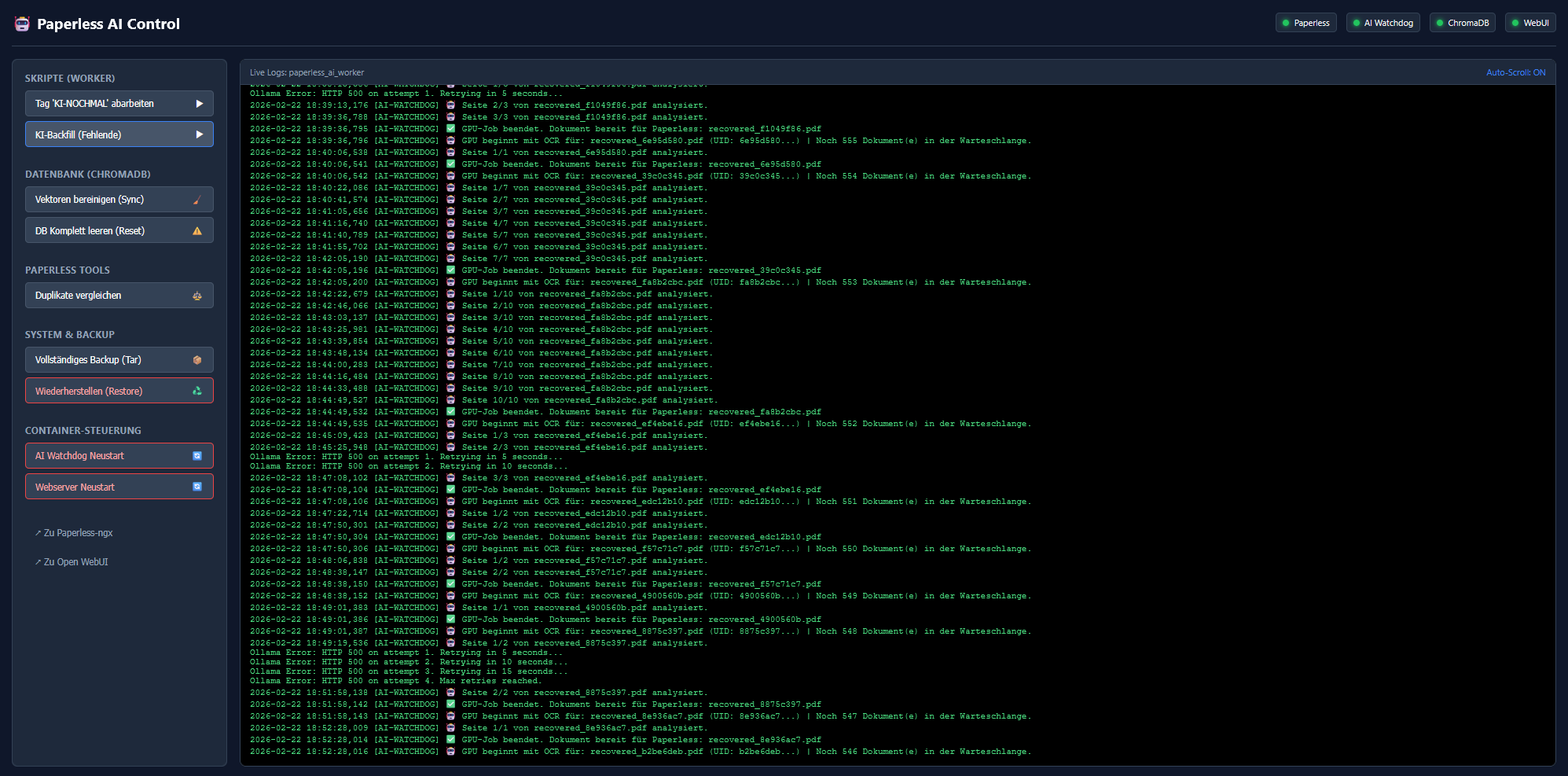
1. Asynchrone Jobs & Die Warteschlange (Producer/Consumer)
Früher blockierte die OCR den Paperless-Eingang. Das ist Geschichte!
-
Der Scanner (Producer): Wenn neue PDFs im scan_input Ordner landen, zieht ein flinker Frontend-Thread sie in Bruchteilen einer Sekunde in einen versteckten ai_staging Zwischenordner. Dort zerlegt die CPU sie hocheffizient in flüchtige Base64-Strings (direkt im RAM).
-
Die GPU (Consumer): Ein asynchroner Hintergrund-Thread nimmt sich diese Bilder aus einer Queue, sobald die Grafikkarte frei ist. Das schwere Vision-Modell rattert die Liste entspannt ab.
-
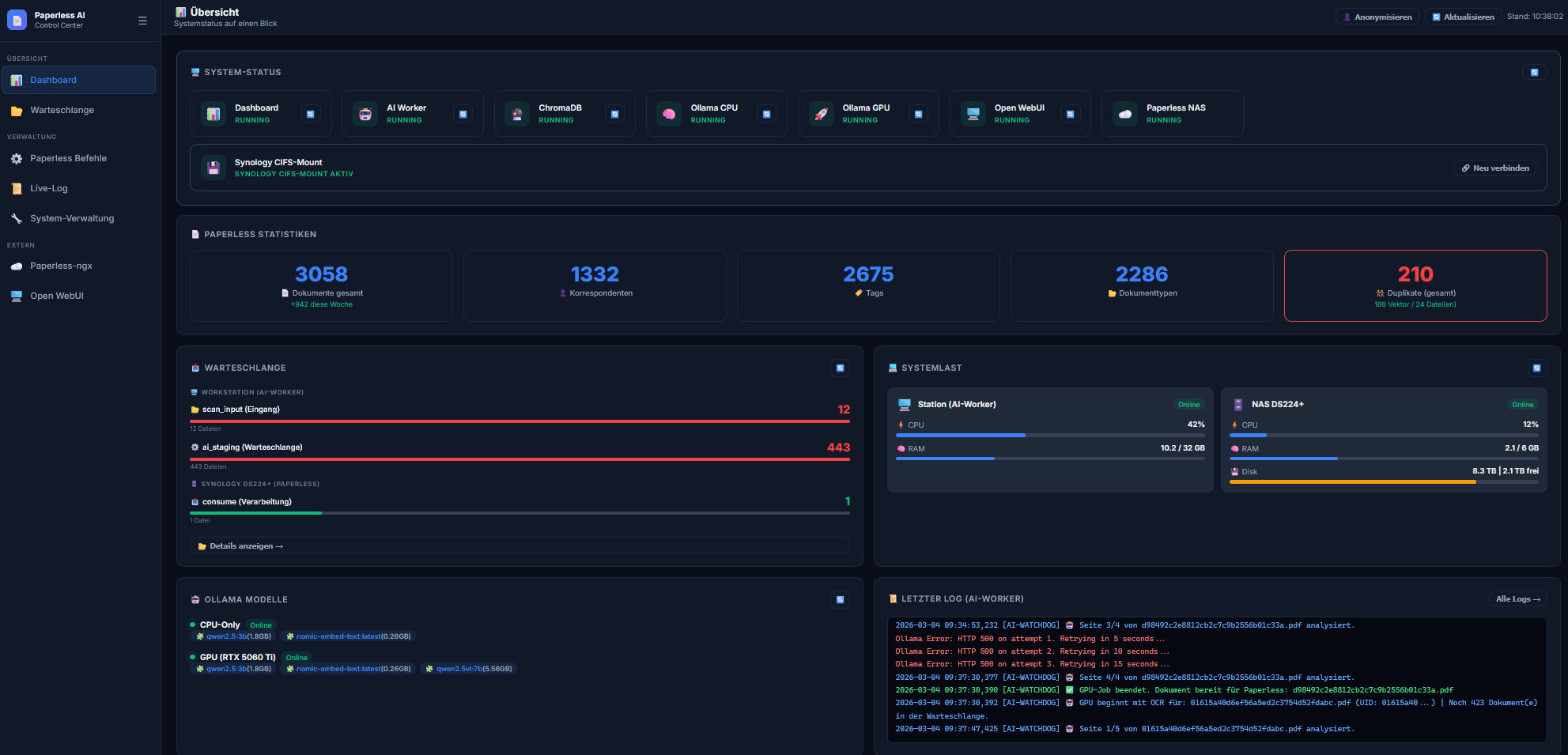
Live-Zähler: In den Docker-Logs steht live: „GPU beginnt mit OCR für: Rechnung.pdf | Noch 19 Dokument(e) in der Warteschlange.“ Paperless kann währenddessen ungestört weiterarbeiten.
2. Absturzsicherheit & „Ghost-Busting“ (Recovery)
Was passiert, wenn der Docker-Container mitten im großen KI-Scan abstürzt?
-
Beim Neustart scannt das System den verborgenen ai_staging Ordner und reiht abgebrochene Jobs automatisch wieder in die Warteschlange ein.
-
Geister-Schutz: Um fiese Duplikat-Fehler in Paperless zu vermeiden, prüft das Skript live über die Paperless-API den Datei-Hash (SHA-256). Liegt das defekte PDF in Wirklichkeit längst sicher im Archiv, löscht das Skript die „Dateileiche“ im Staging-Ordner stillschweigend.
3. Archiv-Integrität & „Hands-off“ bei Originalen
Viele externe KI-Skripte wandeln Bilder brutal in Graustufen um und überschreiben das bunte, gut strukturierte originale PDF physisch auf der Festplatte. Meine Philosophie:
-
Wir belassen das Original (mit allen Farben, Wasserzeichen und Vektoren) absolut unangetastet.
-
In meinem Setup greift die KI auf der Festplatte nichts destruktiv an. Bilder werden nur flüchtig als JSON im RAM analysiert.
-
Paperless verarbeitet das Original nativ zu sauberen PDF/A Dateien. Die KI hängt ihre erkannten Tags, Daten und den extrahierten Text einfach transparent über die API an (ai_post_consume.py).
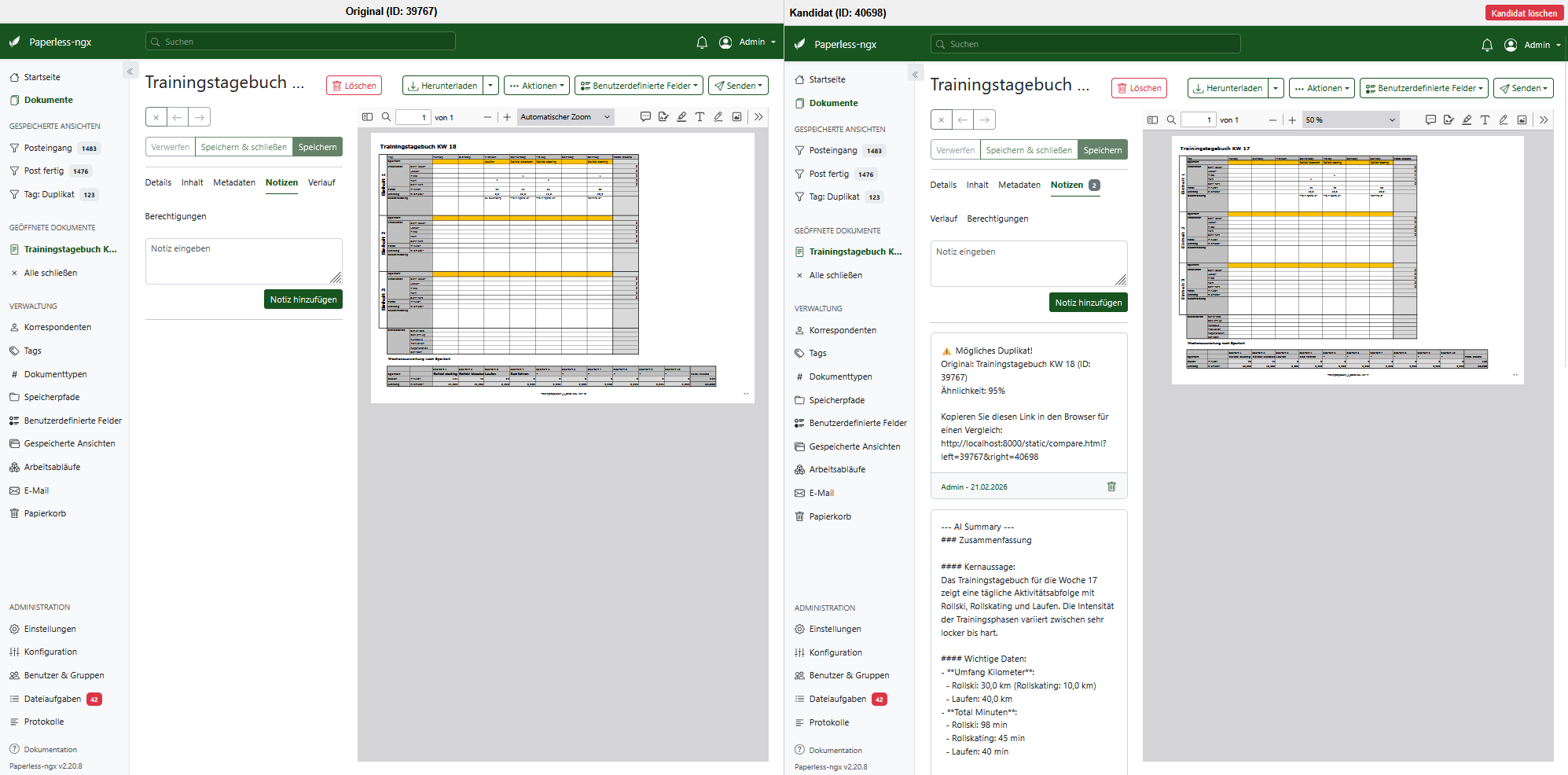
4. Smart Duplicate Detection (Vektor-Ähnlichkeit)
Das Post-Consume Skript berechnet beim Einlesen ein semantisches Text-Embedding des neuen Dokuments und gleicht es über ChromaDB mit dem Archiv ab.
-
Bei z.B. >92% Ähnlichkeit (z.B. derselbe Telekom-Vertrag in zwei minimal verschiedenen PDF-Formaten) wird nicht blind gelöscht.
-
Das Skript vergibt intelligent das Tag „Duplikat“ und hinterlegt eine Notiz ans Dokument mit einem direkten Klick-Link zum Vergleich mit dem Ursprungsdokument. (Die Reihenfolge in den Skripten ist dabei entscheidend!).
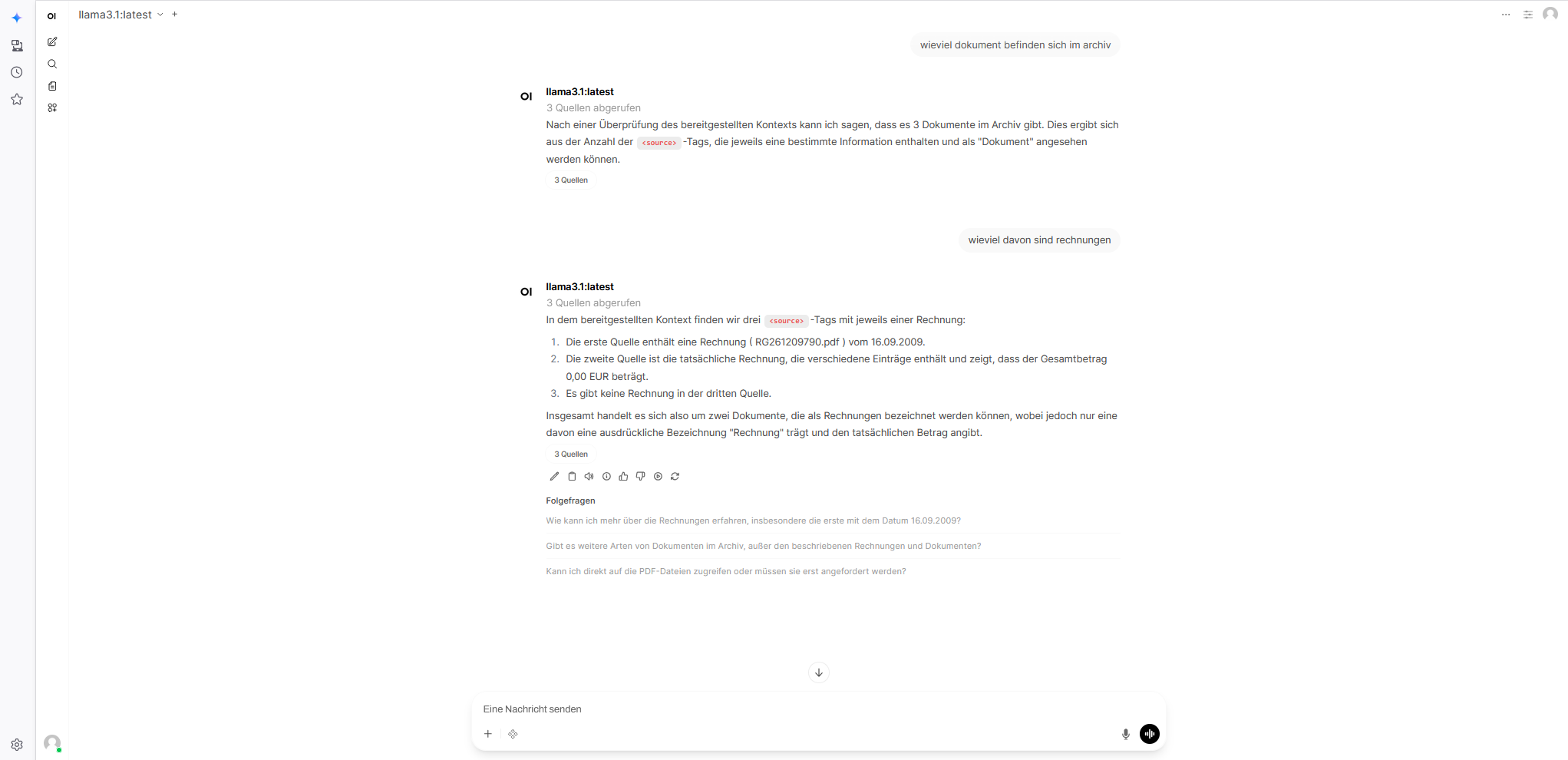
5. Content Summary & RAG Chatbot
-
Zusammenfassung: Die KI liest große Textblöcke und wirft gigantisch schnell eine 3-Satz-Zusammenfassung (Kernaussagen, Fristen, Beträge) als Notiz ans Dokument an.
-
Chatbot (Open WebUI): Die vollständige Anbindung der Paperless-DB an Open WebUI, um mit eigenen Dokumenten privat zu chatten („Welche Versicherungen habe ich letztes Jahr gekündigt?“). Dank eines fixierten WEBUI_SECRET_KEY in der docker-compose.yaml verfallen die Sync-Tokens auch bei Docker-Updates nie wieder!
6. Spezielle Härtefälle: Ausweiskopien
Ausweise und Pässe haben extrem komplexe Sicherheits-Hintergrundmuster, an denen klassische OCRs (und auch Vision-KIs oft) völlig scheitern und „halluzinieren“ (z.B. indem sie nur noch einzelne Ziffern wie eine „9“ ausgeben). Durch rigoroses Prompt-Engineering in der Yaml-Config ist das Vision-Modell nun darauf gedrillt, diese störenden Hologramme chirurgisch auszublenden und sich rein auf Namen, Geburtsdatum und die Behörden-MRZ-Zahlenreihen am unteren Rand zu konzentrieren.
7. Performance Limit: Große Dokumente (> 10 Seiten)
Ein extrem wichtiges Detail zum Schluss: Um die Pipeline vor einem VRAM-Infarkt durch 50-seitige Handbücher zu bewahren, überprüft der Watchdog im initialen, asynchronen Durchlauf strikt nur die ersten 10 Seiten jedes neuen PDFs.
Für alles darüber hinaus gibt es ein beiliegendes Batch-Skript (z.B. process_by_tag.py): Wenn ihr in Paperless feststellt, dass ein Dokument sehr lang ist und ihr zwingendalleSeiten durch die KI jagen wollt, vergebt ihr dem Dokument manuell das Tag"KI-NOCHMAL". Ein abendlicher Cronjob (oder manueller Aufruf) greift dann all diese markierten Mega-Dokumente auf und veredelt sie in aller Ruhe über Nacht komplett!
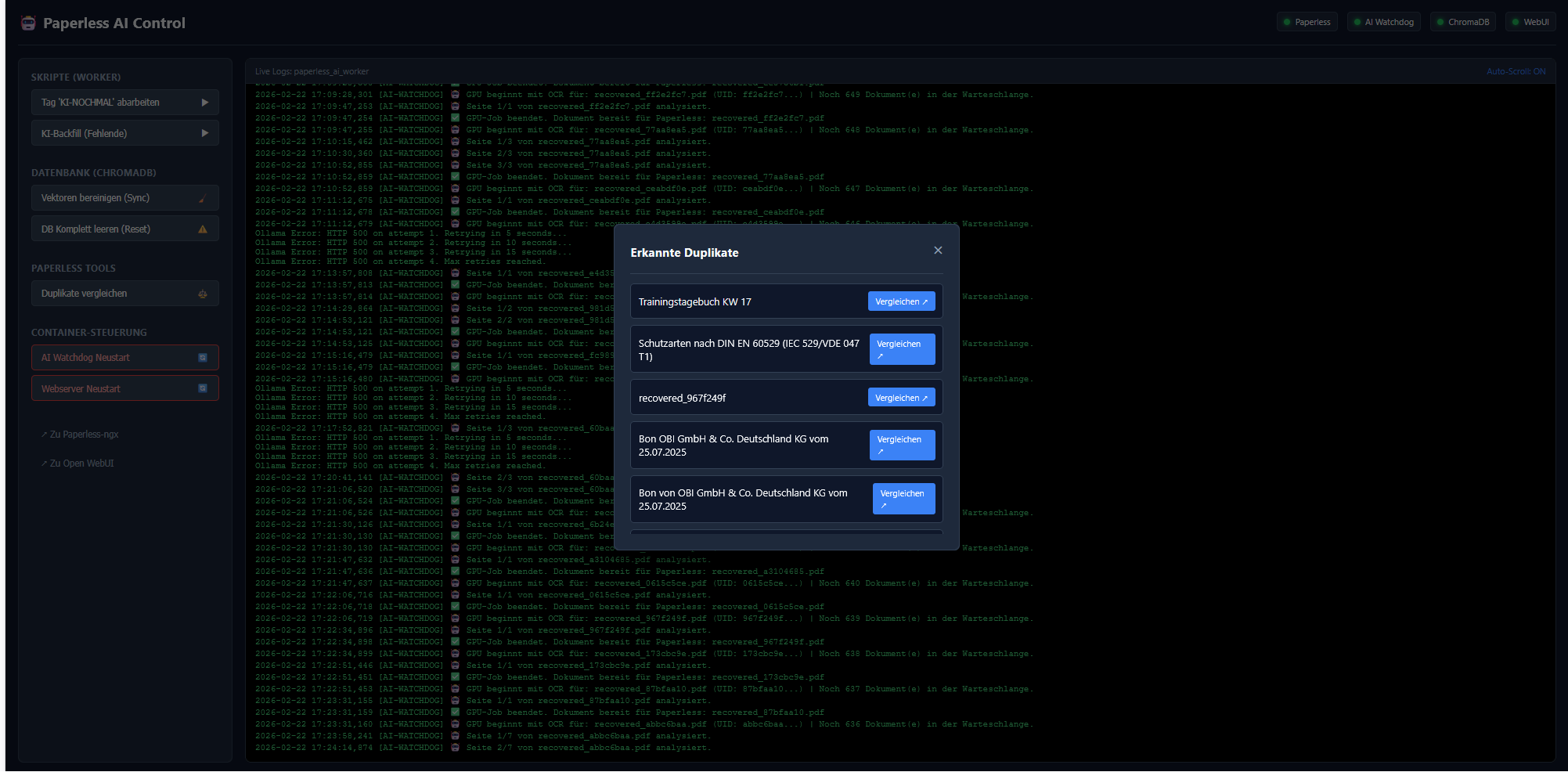
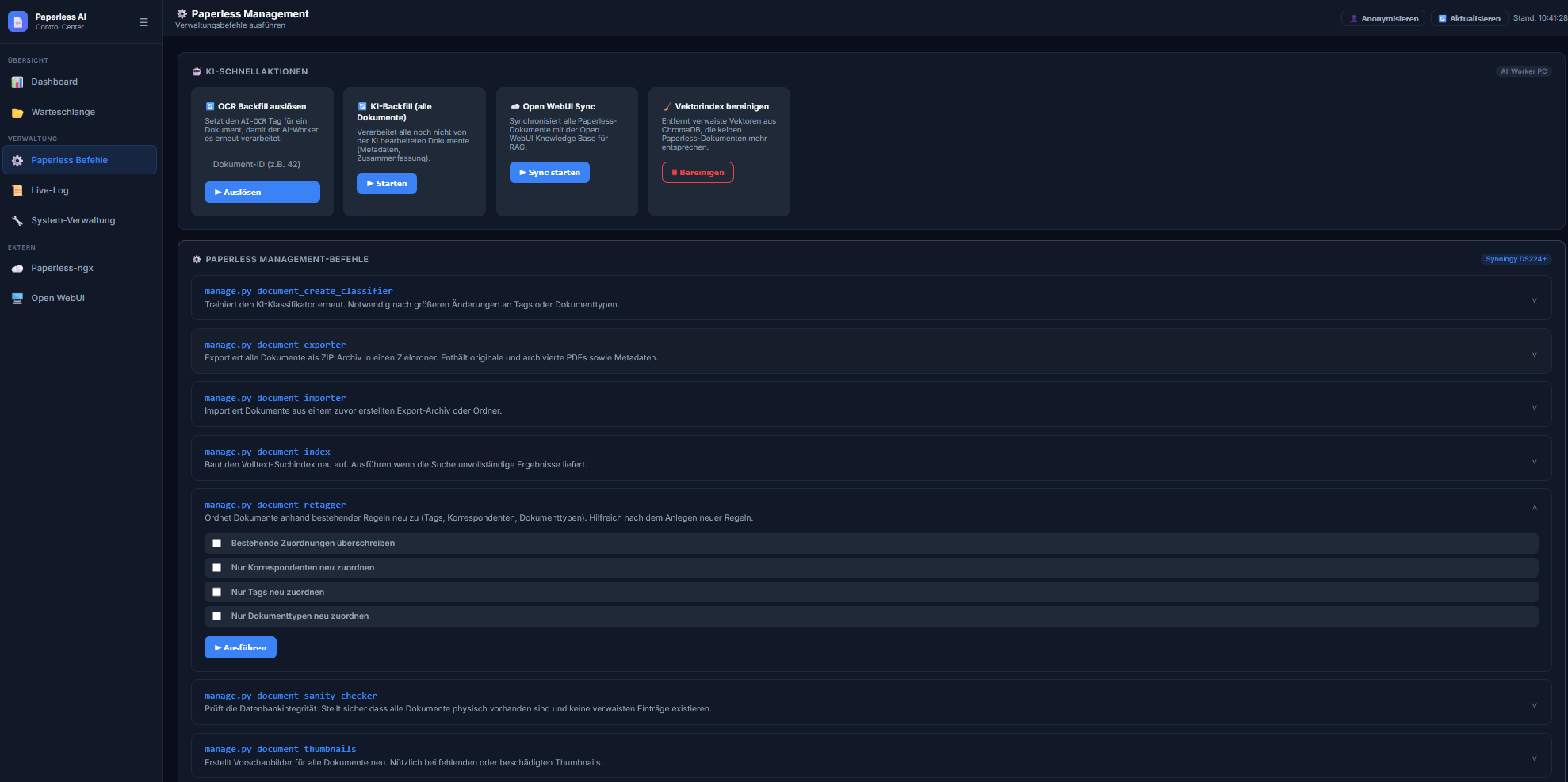
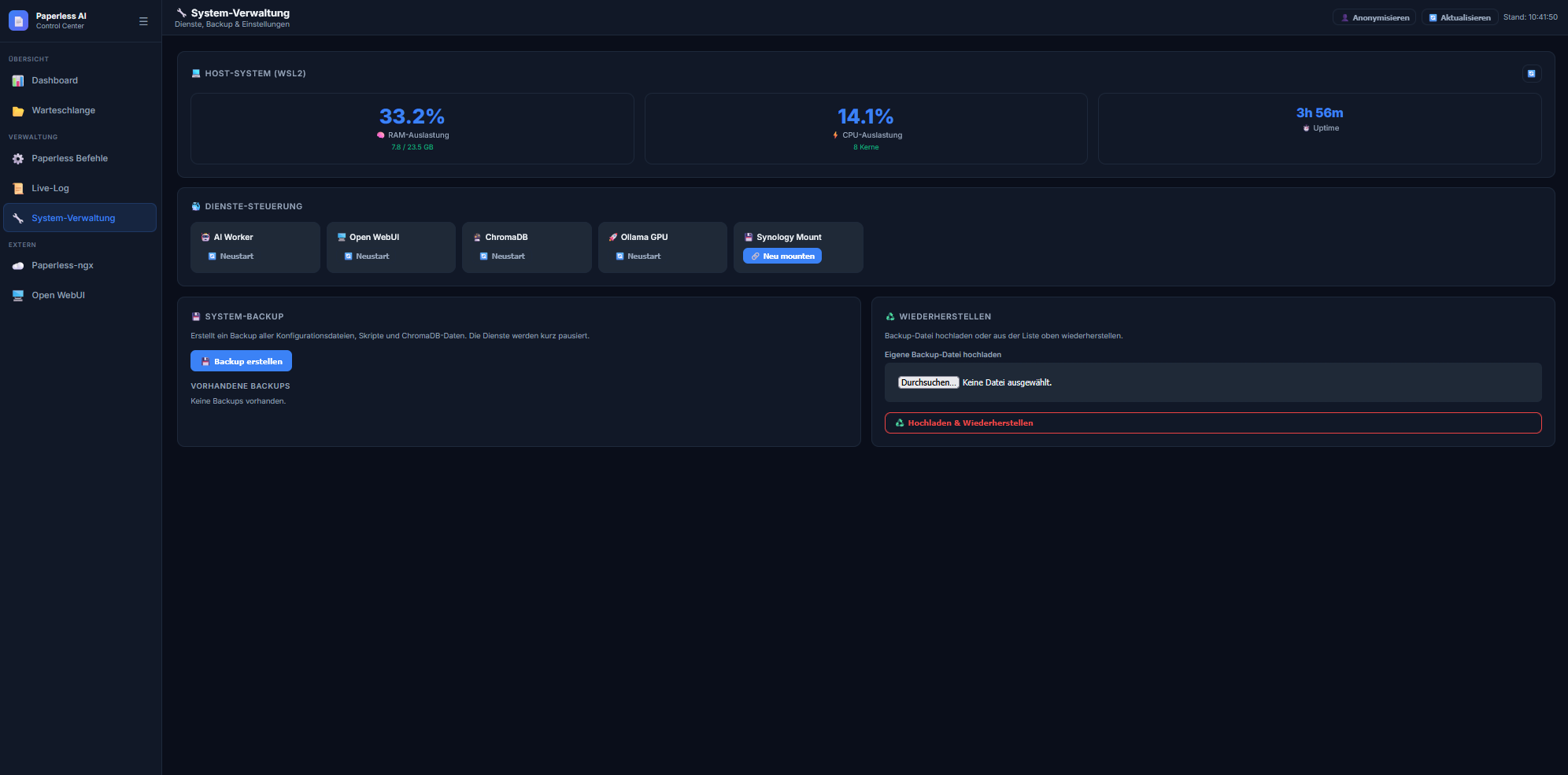
8. Das Paperless AI Control Panel (Web-Dashboard)
Ganz neu hinzugekommen in diesem Export-Paket ist ein leichtgewichtiges Browser-Dashboard (ähnlich wie Portainer, nur spezifisch für diesen KI-Workflow). Unter Port 8050 erreicht ihr ab sofort ein edles Dark-Mode-Interface, um die Container nicht mehr übers Terminal steuern zu müssen:
-
Live Logs: Verfolgt in Echtzeit, was der Watchdog treibt und wie viele Dokumente in der Warteschlange hängen.
-
Skripte triggern: Führt Batch-Verarbeitungen (process_by_tag.py) oder ChromaDB-Aufräumaktionen mit einem simplen Mausklick aus.
-
Duplikate-Verwaltung: Eine clevere Liste aller erkannten Archiv-Duplikate ermöglicht euch per Knopfdruck („Vergleichen“) den sofortigen Side-by-Side-Ansichtssprung in Paperless-ngx.
-
Datensicherheit (Backup & Restore): Ein Button für ein inkonsistenzfreies Komplett-Backup (stoppt kurz alle Services, zieht alle Vektoren, DBs und PDFs in ein .tar.gz Archiv und startet wieder). Ein weiterer Button erlaubt die sofortige Wiederherstellung aus bestehenden Archiven oder direkt per Datei-Upload vom lokalen PC bei komplett frischen Systemen!
 Mein Fazit
Mein Fazit
Durch das radikal entkoppelte Producer/Consumer-Skripting rennt die Pipeline nun auch bei wilden Bulk-Uploads von extrem anspruchsvollen Formaten geschmeidig und logisch nachvollziehbar im Hintergrund durch.
Sollte jemand von euch auf ähnliche Probleme stoßen (zerstörte Archive nach KI-Durchlauf, VRAM-Kollapse, gestrandete Dateileichen in Staging-Ordnern oder scheiternde Ausweiskopien), hoffe ich, dass dieser Workflow als gute Blaupause dient.
Vielleicht gibt das dem ein oder anderen neue Inspiration für eigene Bastelprojekte!
 Ein wichtiger Hinweis zum Schluss (Vibe Coding): ein großer Teil dieses Setup ist im Laufe vieler „Vibe Coding“-Sessions entstanden (viel Trial & Error, LLM-Pair-Programming und kreatives Ausprobieren). Ich übernehme daher keinerlei Garantie für die Lauffähigkeit auf anderen Systemen oder für die absolute Datensicherheit eurer Archive. Wer die Skripte übernimmt, tut dies auf eigenes Risiko – checkt eure Backups!
Ein wichtiger Hinweis zum Schluss (Vibe Coding): ein großer Teil dieses Setup ist im Laufe vieler „Vibe Coding“-Sessions entstanden (viel Trial & Error, LLM-Pair-Programming und kreatives Ausprobieren). Ich übernehme daher keinerlei Garantie für die Lauffähigkeit auf anderen Systemen oder für die absolute Datensicherheit eurer Archive. Wer die Skripte übernimmt, tut dies auf eigenes Risiko – checkt eure Backups! 
Davon abgesehen bin ich aber wahnsinnig gerne bereit, bei der Fehlerbehebung, der Anpassung an andere Systeme oder der initialen Implementierung dieser Lösung in eure Paperless-Instanzen zu helfen. Meldet euch einfach hier im Thread!
Hinweis: Aus Vorsicht teile ich das Installations-Skript samt der zugehörigen ZIP-Datei nicht direkt inflationär hier im Post, sondern schicke es bei ernsthaftem Interesse sehr gerne einfach per kurzer PN (Privater Nachricht) rüber.
Da schon erste Anfragen zum Thema Verteilung auf getrennte Systeme aufkamen:
https://forum.digitalisierung-mit-kopf.de/t/aw-ocr-verbesserung-mit-lokalem-llm/3228/2?u=heiko