Hallo @drnicolas,
wie schon im Beitrag „Paperless OCR verbessern: best practise?“ beschrieben, laufen bei mir die Scans durch einen „scan_input“-Ordner, werden dort veredelt (Auflösung, Helligkeit, Kontrast usw.) und durchlaufen dann einen KI-Server. Dieser kann, im Gegensatz zu Tesseract, nicht nur die einzelnen Zeichen deuten, sondern die Zeichenketten in einen Kontext setzen und daraus sinnvollen Text generieren.
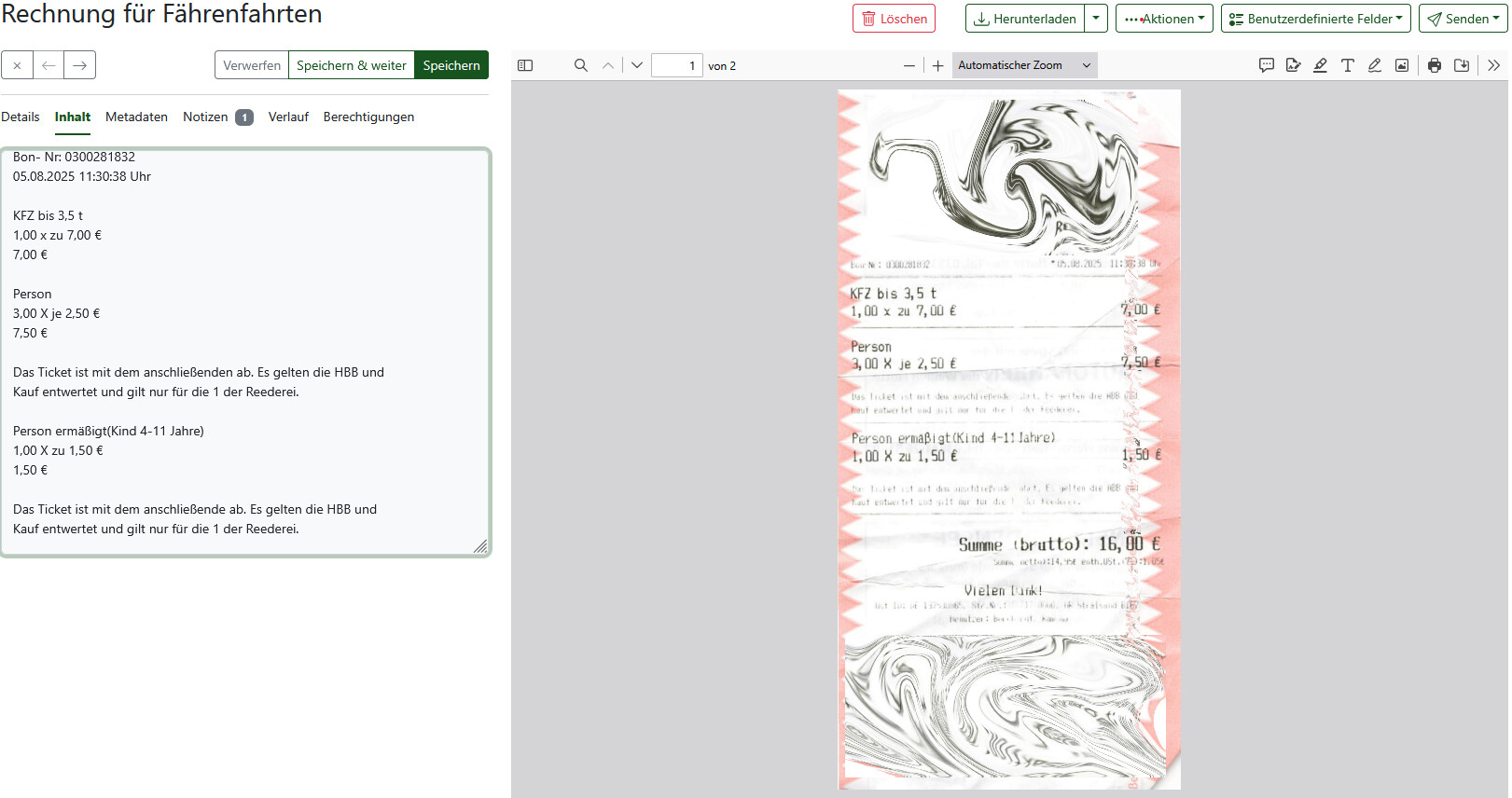
(Bild: einer der Endgegner für Paperless-NGX, man beachte die kleine graue Schrift)
PS: Die Archiv-Datei enthält einen kompletten positionsgetreuen neuen OCR-Layer
Grüße Heiko