Hallo zusammen,
nach gefühlt endlosen philosophischen und technischen Sitzungen mit „Gemini“ melde ich mich mal wieder mit einem Update aus der Automatisierungsecke. Ich habe mein Pre-Consumption-Skript grundlegend überarbeitet und bin mit dem aktuellen Workflow extrem zufrieden.
Vielleicht ist das ja für den einen oder anderen von euch eine Inspiration oder Diskussionsgrundlage.
Der Workflow im Detail:
-
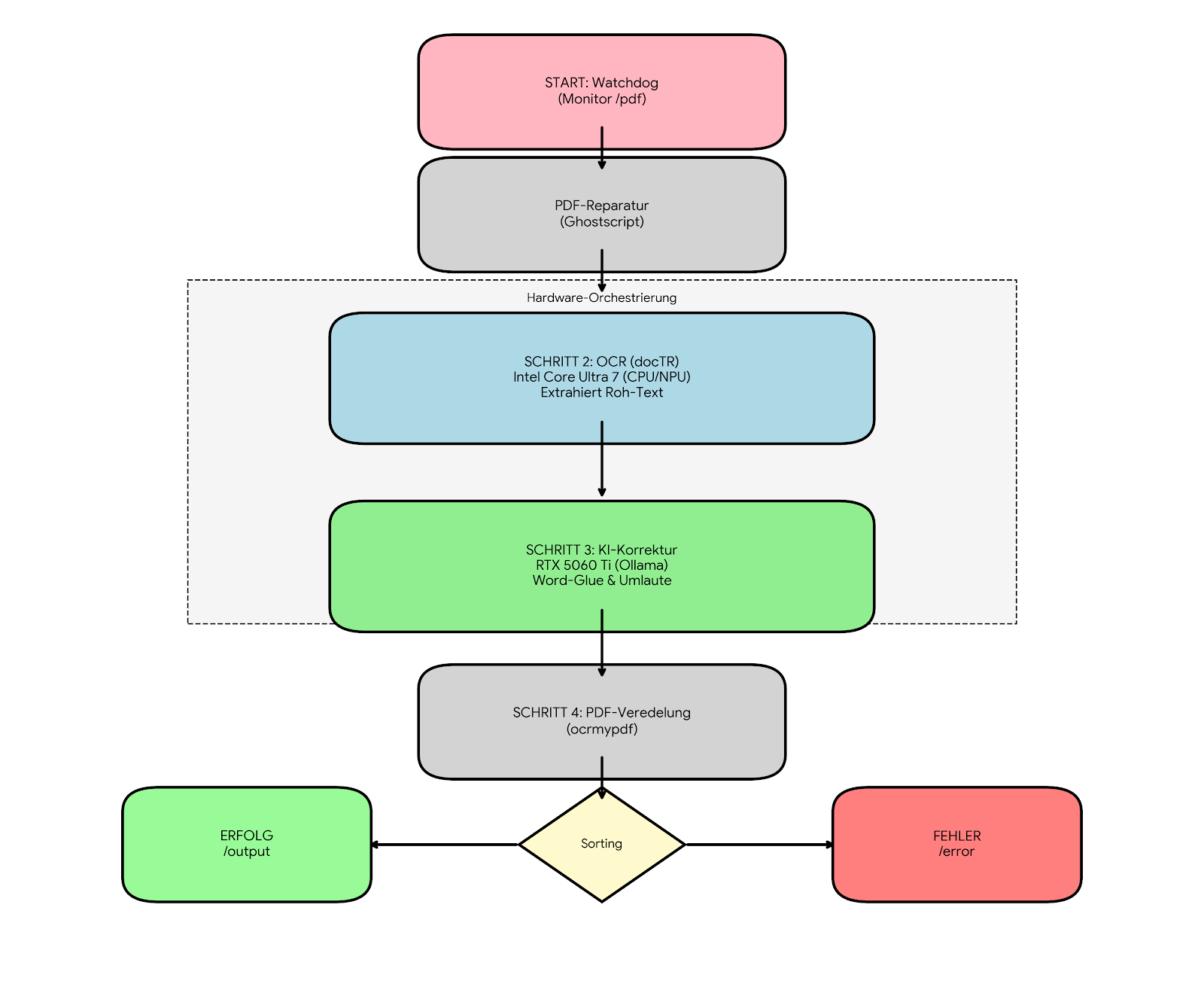
Input: Dokumente kommen entweder als Datei oder direkt vom ScanSnap ix1600 in den zentralen „Inputordner“.
-
Verarbeitung: Hier greift mein Skript. Die PDF wird vorverarbeitet und anschließend direkt in den Consume-Ordner von Paperless verschoben.
-
OCR via Ollama: Das Herzstück ist die Texterkennung außerhalb von Paperless. Ich nutze Ollama mit dem Modell
Keyvan/german-ocr.- Performance: Die Verarbeitungszeit liegt bei einem normalen Dokument bei gerade einmal ca. 5 Sekunden.
-
Paperless-ngx: Da das Dokument bereits perfekt „vorbereitet“ ankommt, verarbeitet Paperless es ohne erneute OCR (Tesseract). Das spart Ressourcen und vermeidet doppelte Arbeit.
-
Finishing: Paperless-AI übernimmt dann den Rest – vor allem die Titelgenerierung (ein Segen für alle, die wie ich zu faul für manuelles Benennen sind).
Warum dieser Weg?
Durch die Auslagerung der OCR auf Ollama ist das System wesentlich flinker. Die Qualität der Texterkennung mit dem German-OCR-Modell ist beeindruckend und Paperless-ngx bleibt schlank, da es nur noch für die Archivierung und die KI-gestützte Metadaten-Analyse zuständig ist.
Wie sieht eure aktuelle Pipeline aus? Habt ihr ähnliche Erfahrungen mit externer OCR-Vorverarbeitung gemacht oder setzt ihr voll auf die Bordmittel von Paperless?