Hallo ! ![]()
Ich möchte dir mein Setup vorstellen, mit dem ich
Paperless-ngx um eine vollständig lokale KI-Pipeline erweitert
habe. Keine Cloud, keine API-Kosten – alles läuft auf dem eigenen Server.
![]() Was macht das System?
Was macht das System?
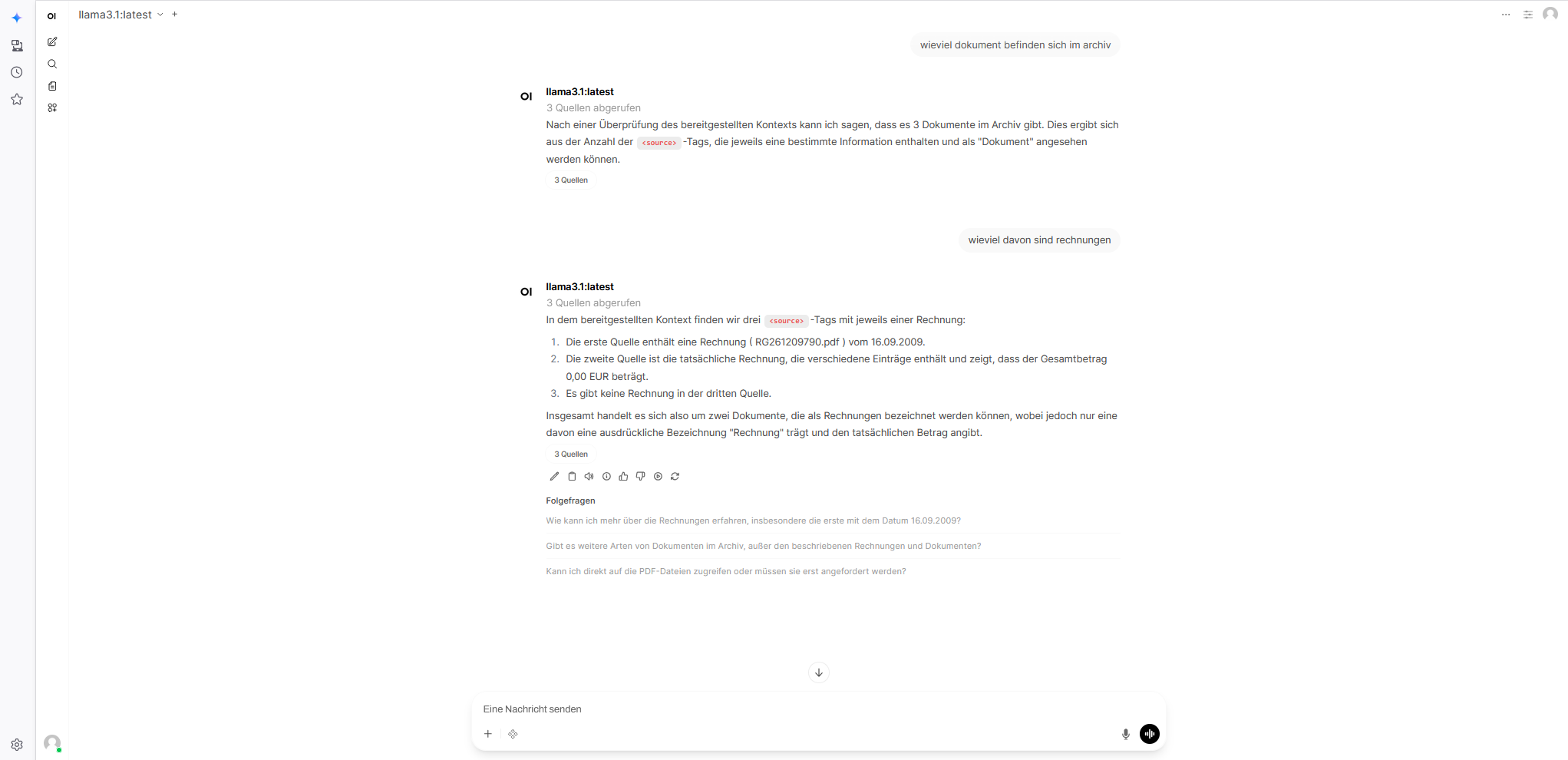
Kurz gesagt: Jedes Dokument, das ich einscanne oder importiere, wird automatisch von einer Vision-KI (Qwen2.5-VL via Ollama) analysiert.
Das Ergebnis:
-
Automatische
Titel-Vergabe (z.B. „Rechnung Telekom Januar 2025“) -
Korrespondent,
Tags und Dokumenttyp werden erkannt und gesetzt -
Hochwertige
OCR direkt aus dem Bild (kein Tesseract-Salat bei Mehrspaltlern!) -
Duplikaterkennung per
Vektor-Ähnlichkeit (ChromaDB) + Binärvergleich -
Optimiertes
Archiv-PDF mit sauberem OCR-Layer
![]() Architektur
Architektur
Das System besteht aus zwei Stufen, die
vollständig in Docker laufen:
Stufe 1: AI Watchdog (Vor dem Import)
Ein eigener Container überwacht den scan_input-Ordner.
Sobald eine Datei auftaucht:
-
Binärer Duplikat-Check (MD5 gegen Paperless-DB)
-
PDF → Bilder konvertieren und optimieren (Schärfung, Kontrast)
-
Vision-AI analysiert jede Seite (OCR + Layout-Erhaltung)
-
Sidecar-JSON mit allen Ergebnissen wird erstellt
-
Original wird unverändert(!) in den consume-Ordner verschoben
(Das Kopieren in den Consume-Ordner bleibt folgenlos)
Stufe 2: Post-Consume Script (Nach dem Import)
Paperless importiert das Dokument und triggert mein
Post-Consume-Script:
-
Sidecar einlesen → Metadaten anwenden (Titel, Tags, Korrespondent, Datum)
-
Content überschreiben mit dem besseren AI-OCR-Text
-
Vektor-Duplikaterkennung via ChromaDB
-
ChromaDB-Indexierung für semantische Suche
-
Archiv-PDF optimieren
-
Tag „paperless-ai“ setzen → Fertig!

![]() Das Besondere:
Das Besondere:
Fail-Safe + Retry
Falls die AI-Analyse im Watchdog scheitert (z.B.
verschlüsseltes PDF, Timeout):
-
Das Dokument wird trotzdem importiert (Fail-Safe)
-
Das Post-Consume-Script erkennt die fehlenden Daten und startet automatisch
einen zweiten Versuch im Container -
Das funktioniert sogar für DOCX und Bilder: Hier wird das von
Paperless erstellte Archiv-PDF für die Vision-Analyse genutzt
![]() Docker-Setup (Komplettes Re-Build eines Paperless-ngx)
Docker-Setup (Komplettes Re-Build eines Paperless-ngx)
Das Ganze läuft mit folgenden Containern:
Container Aufgabe
webserver - Paperless-ngx (Custom Build mit Python-Deps)
ai-worker - Watchdog (überwacht scan_input)
chromadb - Vektordatenbank für Duplikaterkennung
ai-chat - Ollama mit Open-WebUI (Dokumente per Chat durchsuchen)
broker - Redis
db - PostgreSQL
gotenberg - Office-Konvertierung
tika - Textextraktion
Ollama läuft bei mir direkt auf dem Host
(GPU-Zugriff). Kann aber auch als Container integriert werden.
![]() Verwendetes Modell
Verwendetes Modell
-
Qwen2.5-VL:7b via Ollama
-
Läuft bei mir auf Intel Core i7 Ultra, 32 GB-DDR5, Nividia RTX 5060 (16GB VRAM)
-
Verarbeitung: ~30-60 Sekunden pro Seite (je nach Komplexität)
-
Auch auf CPU möglich, dann natürlich langsamer
![]() Besondere Features
Besondere Features
-
Zombie-Erkennung: Binärer Duplikat-Check prüft, ob die Datei physisch existiert. „Geister“
in der DB werden ignoriert. -
ChromaDB Cleanup: Wartungsskript zum Entfernen verwaister Vektoren (maintenance_cleanup_vectors.py).
-
Kein Datenverlust: Originale werden NIEMALS verändert. Alles passiert
auf Kopien/im Archiv-Layer. -
Deutsche Optimierung: Prompts und Metadaten-Extraktion sind auf deutsche
Dokumente optimiert.
![]() FAQ
FAQ
Q: Brauche ich eine GPU? A: Empfohlen, aber
nicht zwingend. Qwen2.5-VL:7b läuft auch auf CPU, dann dauert es nur deutlich
länger.
Q: Funktioniert das auch mit nicht-deutschen Dokumenten?
A: Ja, die Prompts sind auf Deutsch, aber das Modell versteht auch Englisch/andere
Sprachen problemlos.
Credits: Ein großer Teil der Implementierung
wurde mit Unterstützung von Antigravity AI (Google DeepMind)
entwickelt. ![]()