Hands-on: Texterkennung (OCR) durch lokale KI: Endlich Handschrift & Kassenbons erkennen?
Neugierig, wie lokale KI deine Kassenbons in Tabellen verwandelt? In meinem neuesten Video zeige ich dir, wie ein Vision‑Modell wie qwen2.5vl:7b aus einem Foto eines Receipts eine strukturierte Markdown‑Tabelle erzeugt – komplett ohne Cloud‑Abhängigkeit, und teste sogar Handschrift, um zu zeigen, wie viel Potenzial in lokal laufenden Modellen steckt. Willst du mehr lernen, wie du so eine Lösung in dein Dokumenten‑Management integrierst?
Sehr interessant! Ich baue gerade etwas ähnliches:
Ein per pre-consumption-Script aufrufbares Tool, das die PDFs mit Vision-Modellen OCRed und dann an paperless zurückgibt.
paperless-gpt wollte ich auch noch testen, das kann vieles davon auch. Wobei es mir fast lieber ist, eine einfache und verlässliche Toolchain selbst gebaut zu haben, mit der ich alles exakt beeinflussen kann.
Mit welchen Modellen hast du die beste Erfahrung gemacht?
In den letzten Wochen habe ich verschiedene Modelle und Tools getestet, darunter minicpm-v, llama3.2-vision:11b, Qwen3-VL:4b und deepseek-ocr:3b. Besonders deepseek-ocr:3b läuft seit heute Abend stabil und konnte bereits 300 Dokumente erfolgreich verarbeiten.
Parallel dazu habe ich paperless-gpt mit unterschiedlichen Modellen ausprobiert. Leider kam es dabei unabhängig vom verwendeten Modell immer wieder zu Timeouts. Mein letzter Lösungsansatz bestand darin, Ollama über systemctl alle 300 Sekunden neu zu starten, was jedoch keine dauerhafte Verbesserung brachte.
Zusätzlich traten bei paperless-gpt Probleme mit den OCR-Metadaten auf, die teilweise in Form von chinesischen Schriftzeichen sichtbar wurden. Für die Fehlerbehandlung – etwa bei Passwortschutz, PDF/A-Formaten oder Zertifikaten – hatte ich bei paperless-gpt bislang keine geeignete Lösung. Aus diesem Grund entstand die Idee, ein eigenes Skript zu entwickeln.
Ja klar, interessiert mich auch ganz heftig, da die OCR Erkennung von paperless-ngx einfach grottig ist (und die der Scanner/Drucker leider auch nicht viel besser, da sie nahezu auf dem gleichen System aufsetzten).
Als Nächstes würde ich gerne an einem Projekt arbeiten, das mittels n8n einen Workflow erstellt, der VOR Übergabe an paperless-ngx die OCR der PDFs “bereinigt” um sie dann schon sauber an paperless-ngx zu übergeben.
Könnest Du bitte deinen Code (inkl. setup) unter einem neuem Thema in der Kategorie “Vorstellung: KI-Workflows” posten?
Interessiert mich, wie Du’s von der Seite angegangen bist.
ich frickel noch herum. Bin zur Zeit noch nicht mit der Geschwindigkeit zufrieden. Bei ca. 8000 Dokumenten im Paperless müssten zur Zeit alle wieder in den Consume-Ordner geworfen werden. Allein die Zeit für die OCR mit KI wären 60 sec pro Seite mit einen Vision-Modell der Größe 6 GByte und höher. Das dauert mir zu lange.
ich werfe mal noch doctr in den Raum. Nicht LLM-basiert, aber Machine Learning und auch auf einer GPU ausführbar.
Teste ich auch gerade parallel zu den LLMs mit teilweise überraschend guten und vor allem schnellen Ergebnissen. Hätte auch den Vorteil, dass es auf CPUs richtig gut läuft und damit sogar auf einem NAS einsetzbar wäre.
dass unsere Codes nicht alle perfekt sind ist eh klar. Aber es geht mehr um das wie. Meinen den ich gepostet habe ist garantiert nicht fehlerfrei… Geht mehr um den workflow. Das Modell und die Große muss sich dann eh jeder selbst suchen, was auf seinem Rechner läuft.
nach gefühlt endlosen philosophischen und technischen Sitzungen mit „Gemini“ melde ich mich mal wieder mit einem Update aus der Automatisierungsecke. Ich habe mein Pre-Consumption-Skript grundlegend überarbeitet und bin mit dem aktuellen Workflow extrem zufrieden.
Vielleicht ist das ja für den einen oder anderen von euch eine Inspiration oder Diskussionsgrundlage.
Der Workflow im Detail:
Input: Dokumente kommen entweder als Datei oder direkt vom ScanSnap ix1600 in den zentralen „Inputordner“.
Verarbeitung: Hier greift mein Skript. Die PDF wird vorverarbeitet und anschließend direkt in den Consume-Ordner von Paperless verschoben.
OCR via Ollama: Das Herzstück ist die Texterkennung außerhalb von Paperless. Ich nutze Ollama mit dem Modell Keyvan/german-ocr.
Performance: Die Verarbeitungszeit liegt bei einem normalen Dokument bei gerade einmal ca. 5 Sekunden.
Paperless-ngx: Da das Dokument bereits perfekt „vorbereitet“ ankommt, verarbeitet Paperless es ohne erneute OCR (Tesseract). Das spart Ressourcen und vermeidet doppelte Arbeit.
Finishing:Paperless-AI übernimmt dann den Rest – vor allem die Titelgenerierung (ein Segen für alle, die wie ich zu faul für manuelles Benennen sind).
Warum dieser Weg?
Durch die Auslagerung der OCR auf Ollama ist das System wesentlich flinker. Die Qualität der Texterkennung mit dem German-OCR-Modell ist beeindruckend und Paperless-ngx bleibt schlank, da es nur noch für die Archivierung und die KI-gestützte Metadaten-Analyse zuständig ist.
Wie sieht eure aktuelle Pipeline aus? Habt ihr ähnliche Erfahrungen mit externer OCR-Vorverarbeitung gemacht oder setzt ihr voll auf die Bordmittel von Paperless?
Was ich aber nicht ganz verstehe:
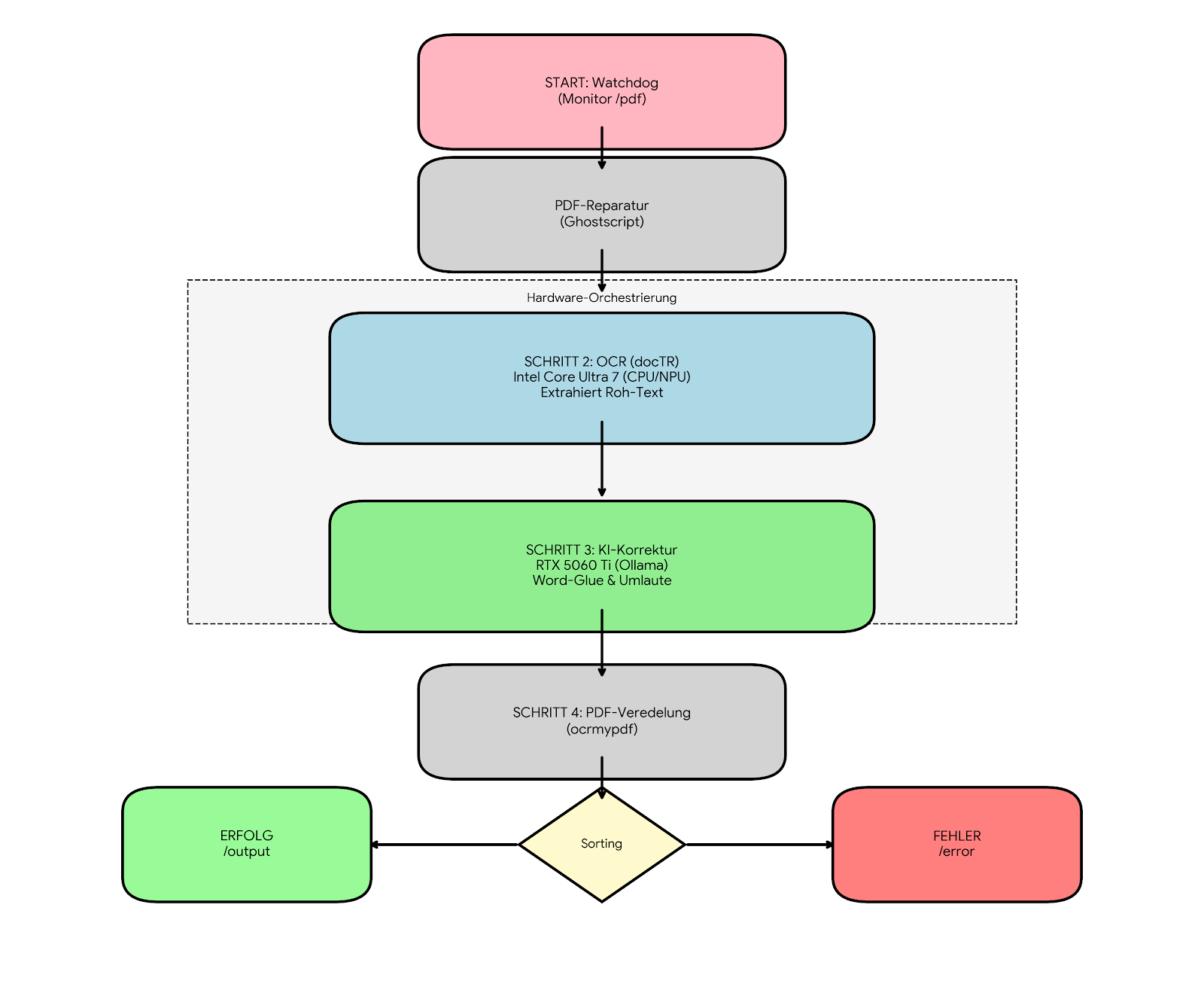
In deiner Grafik steht, dass du docTR nutzt und die KI nur korrigiert, in deinem Text steht, dass du das OCR-LLM nutzt. Evtl hast du eine frühere Version des Workflows als Bild hochgeladen?
Edit:
Zweite Frage: Hast du den Workflow auch mal mit langen Kassenzetteln getestet? Meiner Erfahrung nach brechen hier viele vision-LLMs ab, man muss die Bilder vorher an leerzeilen teilen, sofern eine bestimmte Größe überschritten wird.
Hallo Stefan, da ich hier wieder einmal zwei Fliegen mit einer Klappe schlagen wollte, ist dieses Konstrukt.
Ich lass das Skript auch über all meine “alten” Dokumente drüberlaufen und da ich die Positionsdaten der einzelnen Wörter brauch um Text aus den Dokumenten heraus zu kopieren wurde dies vorher durch “Tesseract” erledigt (komplett neuer OCR Layer). Diese Aufgabe übernimmt jetzt docTR und übergibt den Rohtext an Ollama zur Korrektur den einzelnen Wörter im Kontext zu Text. Danach wird wieder alles zu einem “veredelten” PDF zusammengefügt und abgespeichert. Zuerst habe ich Bilder an die KI direkt geschickt, was eine drei bis vierfache Laufzeit bedeutet hat. Und ja ich ich muss den Text blockweise an Ollama schicken, da es sonst zum Überlauf des NVRAM kommt und Ollama einen Fehler [500] ausgibt oder ganz stehen bleibt (was auch bei großen Dokumenten oder Fehlern im Dokument bei Paperless-gpt passierte). Übrigens Endgegner waren selbst gescannte Zeitschriften (65 Seiten) und ein Buch in digitaler Form ( 780 Seiten) sowie 100 Dokumente in einem Stück.
Deinen Workflow find ich sehr ausgefeilt! Genau dort wo ich hin will!
Würdest Du so nett sein und Deine Schritte 2 und 3 als Code teilen?
Ich bin leider in den pre-consumption-skripts nicht so bewandert. Hast Du die mit n8n erstellt?
Ich bin von Keyan Modell auch angetan gewesen, jedoch hat es mir via paerless-gpt immer den code-block von markdown hineingeschrieben (Aber das ist wahrscheinlich zusätzlich durch das Promt in paperless-gpt getriggert worden, dass den Text in Marktdown will. Allerdings sagt, dass es den Code Block nicht mitkopieren soll, welches dieses Modell nicht versteht). Was ich nicht testen konnte ist, ob es bei englischen Texten auch gut funktioniert?
Ich bin im Augenblick dabei, mit Agenten in Ckaude Code große Mengen an Daten in Markown zu konvertieren. Hierbei handelt es sich um komplette Bücher, juristische Kommentare, ganze Gesetze wie z. B. die DSGVO mit allen Artikeln und Erwägungsgründen etc. Das Ganze wird dann in Obsidian gespeichert, um es für Menschen konsumierbar zu machen, und parallel in einer Vektordatenbank gespeichert, auf die dann eine KI Zugriff hat. Das Ergebnis ist bisher nicht optimal, da einige Bereiche (z. B. Tabellen) nicht erkannt und richtig verarbeitet werden. Außerdem, man kann es sich denken, ist das Spiel recht tokenintensiv. Um es freundlich auszudrücken. Daher habe ich großes Interesse, das System lokal zu betreiben, zumal die OCR-Ergebnisse im Video einwandfrei waren.
Tatsächlich ist der Kurs komplett unabhängig von deiner Hardware. Solange Ollama auf deinem Gerät läuft, kannst du den Kurs nutzen. Ich gehe lediglich in einem Spezialkapitel darauf ein, wie man sich einen solchen Server auf Basis frei verfügbarer Hardware-Komponenten selbst zusammenbauen kann, weil mir diese Unabhängigkeit von vorgefertigten mini-PCs (wie Mac Studio etc). wichtig ist.
Aber wenn du mir genau sagst, was dir inhaltlich noch fehlen würde, wäre ich dir natürlich sehr verbunden. Vielleicht hakt es auch nur an der Kommunikation der genauen Kursinhalte (dass wir genauer beschreiben, mit welcher Hardware es klappt)?
@Stefan Vielleicht ist das, was ich suche, zu speziell und zu kleinteilig. Ich habe Ollama auf dem Mac und (um den Arbeitsspeicher möglichst frei zu halten), Docker und webUI (neben anderen Docker-Installationen) auf meinem NAS installiert. Mich interessiert eigentlich nur der Anwendungsteil mit OCR und die Konvertierung zu Markdown. Allerdings zeigt mir das Modell qwen3:8b an, dass es weder ORC noch Bilder erkennen kann und ich erst das PDF mit einem OCR-Tool lesbar machen muss. Das ist allerdings kontraproduktiv, weil Tabellen nicht einwandfrei erkannt und Texte aus Darstellungen extrahiert werden. Ich habe also daher das Gefühl, dass ich die Hälfte des Kurses eigentlich nicht benötige, da meine Umgebung stabil läuft und die andere Hälfte nicht meinem Informationsbedürfnis entspricht.
Ich sprach es schon einmal in einem meiner früheren Posts an: Gerade bei dem, was Du anbietest, könnte es sinnvoll sein, kurze Infoblöcke anzubieten, mit denen jeder seine eigenen Kursinhalte zusammenstellen kann. Die Blöcke würden einzeln abgerechnet, sind also im Prinzip “Kurse” mit ein bis drei Lektionen (z. B. OCR mit Ollama” und “Konvertierung von PDF in Markdown” [nur um mal Ideen einzustreuen]). Die Blöcke für’n kleinen Taler angeboten wären, dann sicher ein Nobrainer, denn sie lösten ein konkretes Problem SOFORT und der User müsste nicht Ballast mit erwerben, den er eigentlich nicht braucht.
Hallo Stefan, zunächst erstmal herzlichen Dank für deine tolle Arbeit. Deine Themen, die Aufbereitung in den Kursen sind super hilfreich und ihr Geld wert.
Auch wenn ich inhaltlich nicht auf deinem und dem Niveau der anderen hier im thread unterwegs bin, so sehe ich für mich zum o. g. Thema der OCR Qualität dennoch ebenfalls Handlungsbedarf, den ich alleine nicht optimiert bekomme.
Die doch sehr eingeschränkte OCR Qualität war mir bisher gar nicht so bewusst, nachdem ich aber mit paperless-ai via Ionos AI Hub und verschiedenen LLMs versucht habe, konsistente Ergebnisse hinsichtlich Erkennung Dokumenttyp und Korrespondent zu erzielen, stieß ich auf den Umstand der doch häufig unzureichenden OCR Qualität mit zahlreichen Artefakten und Phantomzeichen.
Deine im Video vorgeführten Ergebnisse erscheinen qualitativ dagegen aus einer anderen Welt zu stammen.
Von daher, lass uns bitte daran teilhaben. Ob in der KI Masterclass oder auch anderswo. Würde mich freuen da endlich mit deiner Unterstützung und der Community hier voran zu kommen.
Also, bin gespannt, was du wie entscheidest und wie es sich hier diesbezüglich weiter entwickelt.
 durch lokale KI: Endlich Handschrift & Kassenbons erkennen?")