Mein Paperless-ngx Hybrid AI-Setup: NAS trifft auf GPU-Power (Ollama + Open WebUI + RAG)
Hallo zusammen,
ich wollte euch heute mal mein aktuelles Dokumenten-Setup vorstellen, an dem ich in den letzten Wochen intensiv gefeilt habe. Vielleicht ist es für den einen oder anderen eine Inspiration, der vor dem gleichen Problem steht wie ich: Ein NAS ist super für Storage, aber zu schwach für moderne KI-Anwendungen.
Hier ist mein „Best of Both Worlds“ Ansatz: Paperless-ngx Dual-Host Setup.

Review
System Workflow Concept
 Die Architektur: NAS & PC Hand in Hand
Die Architektur: NAS & PC Hand in Hand
Statt alles auf die Synology zu quetschen, habe ich die Last verteilt:
-
Synology NAS (DS224+): Beherbergt den Paperless-Webserver, die Datenbank und den Dateispeicher. Hier liegen die Dokumente sicher und im Raid.
-
Windows 11 PC (mit WSL2 & RTX 5060 Ti): Hier schlägt das Herz der KI. Dank der 16 GB VRAM laufen Ollama und ChromaDB flüssig im Hintergrund.
 Der Workflow: Automatisierung pur
Der Workflow: Automatisierung pur
Mein Setup nutzt einen AI-Watchdog, der den scan_input Ordner überwacht. Sobald ein neues Dokument reinkommt, passiert Folgendes:
-
High-Quality OCR: Falls das PDF kein OCR hat, schickt der PC es an die lokale KI für eine Textextraktion.
-
Metadata Magic: Eine KI analysiert den Text und schlägt Titel, Datum, Korrespondent und Tags vor.
-
Vektorbasiertes Duplicate-Checking: Bevor ein Dokument im NAS landet, prüft ChromaDB via Vektor-Similarity, ob ich das Dokument (oder ein sehr ähnliches) schon einmal hochgeladen habe. Falls ja, wird es markiert und aussortiert.
-
RAG-Integration: Alle Dokumente werden automatisch in die Knowledge-Base von Open WebUI synchronisiert.
Der „Retro“-Turbo: Nachbearbeitung von Bestandsdaten
Ein besonders mächtiges Feature ist die gezielte Nachbearbeitung von Dokumenten, die bereits seit Jahren in Paperless liegen:
-
Der
AI-OCRTrigger: Vergebe ich in Paperless den TagAI-OCR(oder einen anderen konfigurierten Trigger), erkennt mein PC-Worker das innerhalb von Sekunden. -
Batch-Processing: Die KI wird dann auf das Bestandsdokument losgelassen, führt ein hochqualitatives OCR durch, extrahiert fehlende Metadaten und fügt eine Zusammenfassung in die Notizen ein.
-
Auto-Cleanup: Nach erfolgreicher Bearbeitung entfernt das System den Trigger-Tag automatisch und hinterlegt eine Erfolgsnotiz. So lassen sich tausende Dokumente über Nacht „smart“ machen.
 Chatten mit den Dokumenten
Chatten mit den Dokumenten
Das Highlight ist die Einbindung von Open WebUI. Ich kann meine gesamte Paperless-Bibliothek einfach „fragen“:
-
„Wann läuft meine KFZ-Versicherung ab?“
-
„Fasse mir die letzte Stromrechnung zusammen.“ Die KI greift direkt auf die synchronisierten PDFs zu und liefert Antworten basierend auf meinen echten Daten (RAG - Retrieval Augmented Generation).
 Custom Fixes & Stabilität
Custom Fixes & Stabilität
Um das Ganze alltagstauglich zu machen, mussten einige Hürden genommen werden:
-
JBIG2 Support: Custom Docker-Build für Open WebUI, um auch ältere/komprimierte PDFs lesen zu können.
-
PDF-Rescue-Patch: Ein eingebauter Monkey-Patch verhindert Abstürze bei fehlerhaften Bilddaten in PDFs.
-
Dashboard: Ein zentrales Dashboard zeigt den Status aller Container und erlaubt Backups auf Knopfdruck.
Hier ein kurzes Beispiel für den OCR-Layer (High-Quality OCR):
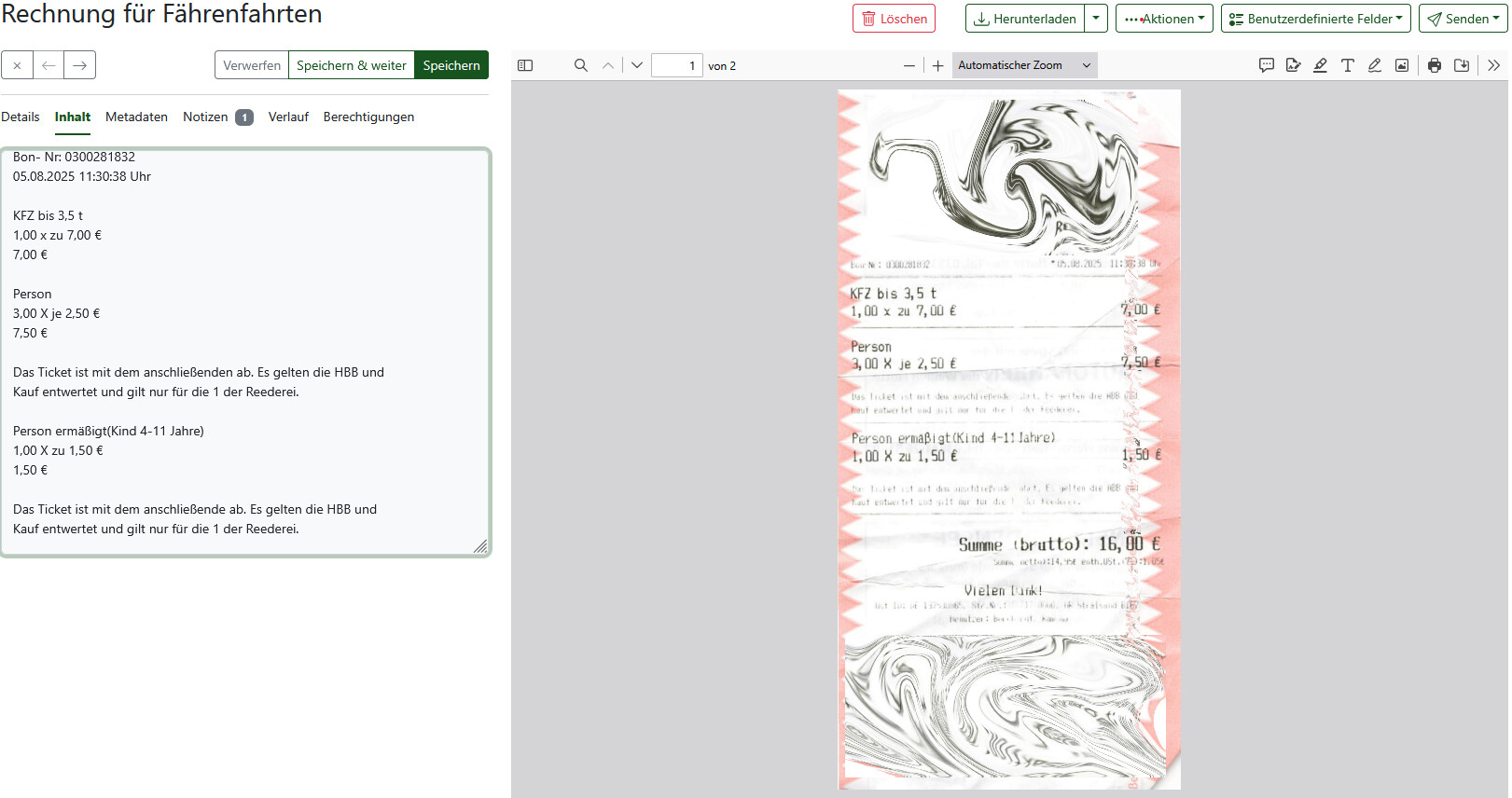
![]() Wichtiger Fallstrick: Wer Ollama bisher als systemd-Dienst (
Wichtiger Fallstrick: Wer Ollama bisher als systemd-Dienst (systemctl) betrieben hat, sollte diesen vor dem Start der Docker-Container deaktivieren. Laufen beide parallel, teilen sie sich die GPU – die Instanzen blockieren sich gegenseitig im VRAM, was zu sporadischen Connection reset-Fehlern und GPU-Hangs führt. Nach systemctl disable --now ollama und Port-Anpassung in der Config (11434 → 11436) läuft alles deutlich stabiler.
Paperless-ngx AI Control Center (Dual-System Control)
weiterhin möchte ich euch mein Dashboard für ein erweitertes Paperless-ngx AI Setup vorstellen. Das Besondere an diesem Setup ist die hybride Architektur:
-
Synology DS224+: Hostet die Paperless-Instanz, die PostgreSQL-Datenbank und das Medien-Archiv.
-
AI-Worker PC (WSL2): Übernimmt die rechenintensiven Aufgaben wie OCR-Backfill, Vektor-Generierung (Ollama/ChromaDB) und Dokumenten-Klassifizierung per LLM.
Da die Verwaltung über zwei Systeme (NAS und PC) schnell unübersichtlich wurde, habe ich ein zentrales Control Center entwickelt.
 Das Dashboard auf einen Blick
Das Dashboard auf einen Blick
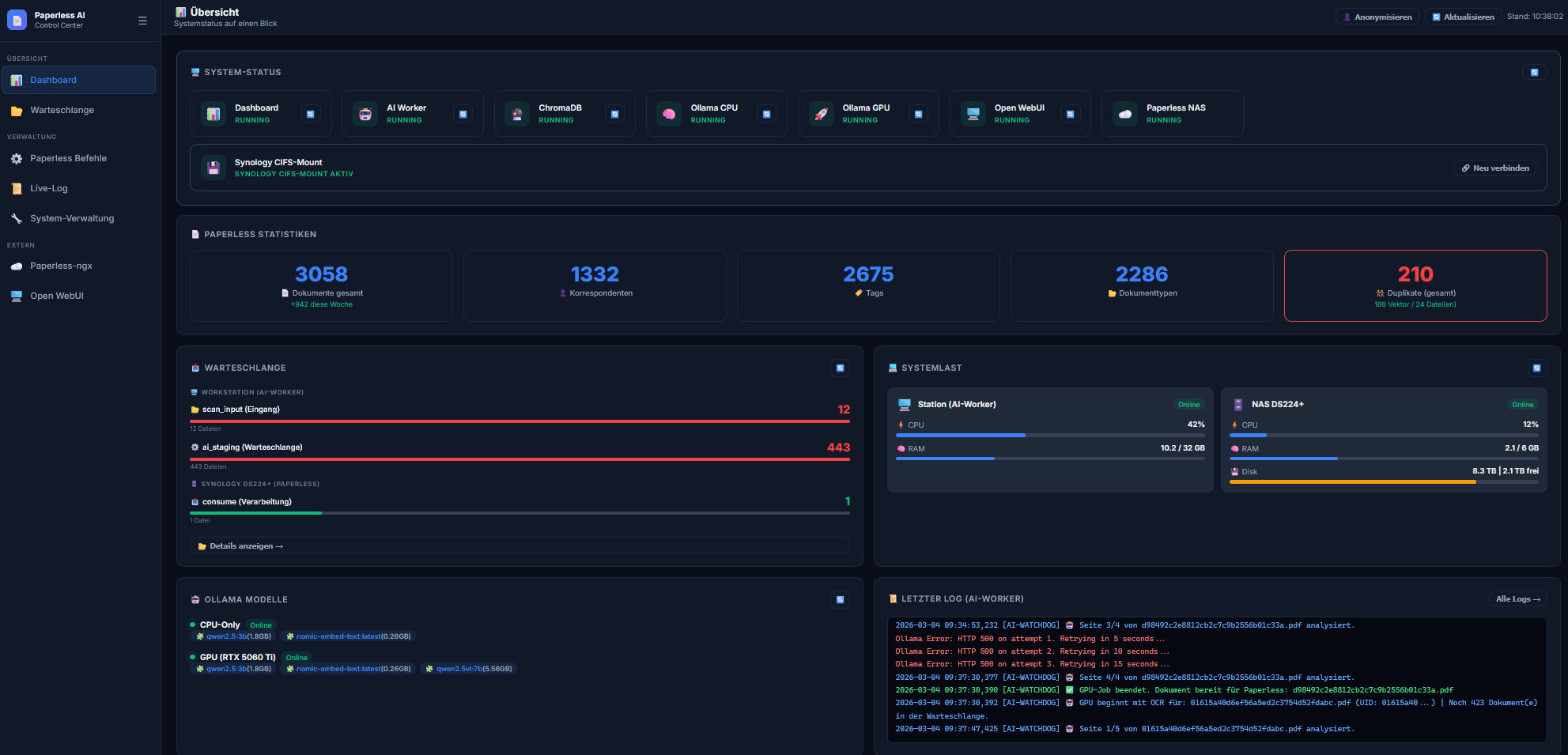
Kernfunktionen:
-
Dual-System Monitoring: Echtzeit-Statistiken über CPU- und RAM-Last beider Systeme. So sehe ich sofort, ob die KI-Workstation gerade unter Volllast arbeitet oder ob die Synology beim DB-Indexieren ins Schwitzen kommt.
-
Intelligente Warteschlangen-Steuerung: Die Warteschlange wird präzise anhand der PDFs im Staging-Ordner (
ai_staging) berechnet. Man sieht genau, wie viele Dokumente noch auf die KI-Verarbeitung warten, bevor sie in den Paperless-Eingang wandern. -
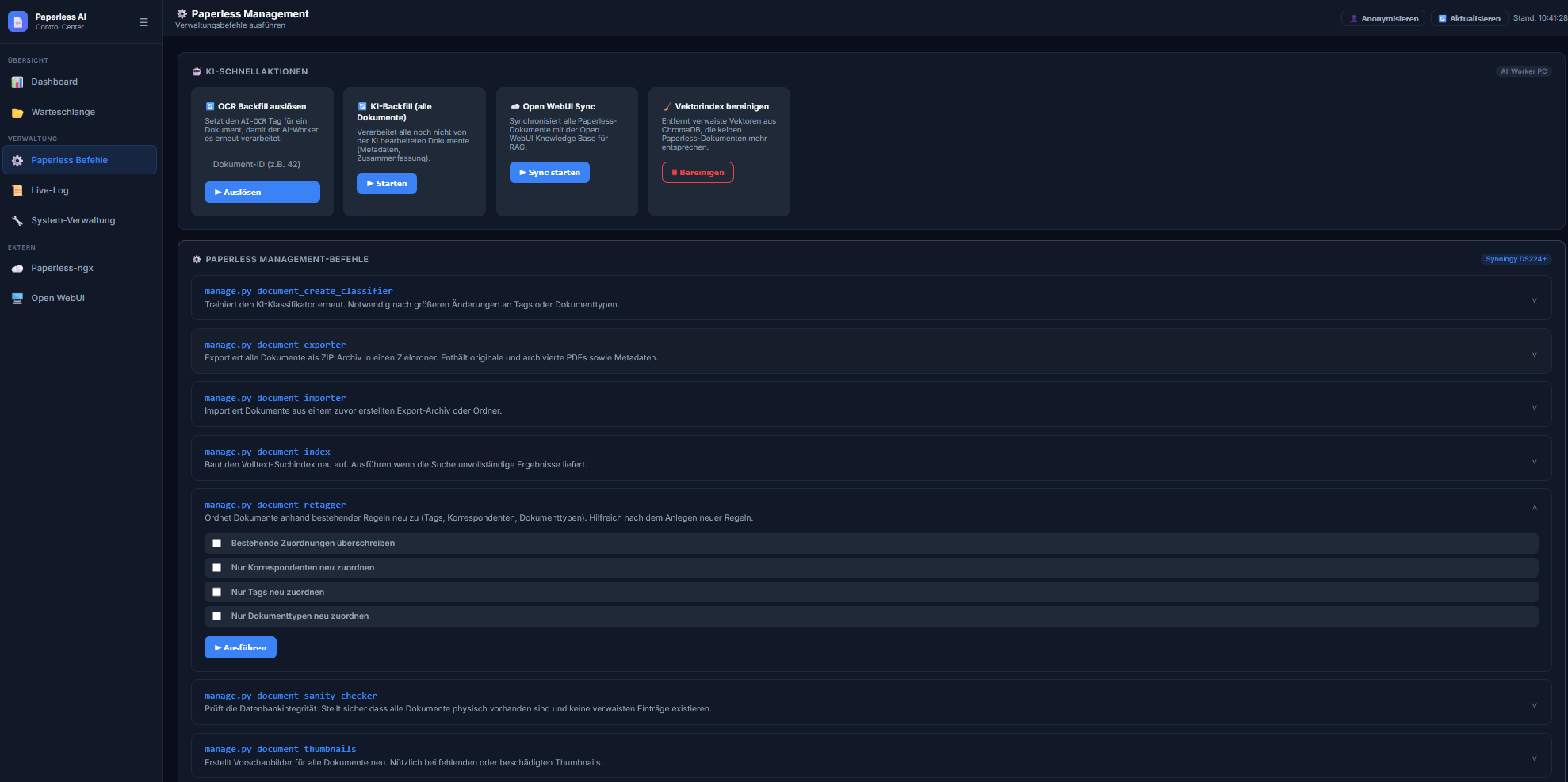
Management-Tools (Remote via SSH): Ich kann Paperless-Managementbefehle (wie
sanity_checker,document_retaggeroderdocument_exporter) direkt aus der Web-UI starten. Diese werden sicher per SSH innerhalb des Docker-Containers auf der Synology ausgeführt. -
Kombinierte Duplikat-Erkennung: Das System zählt sowohl „harte“ Dateiduplikate im Eingangsordner als auch inhaltliche Duplikate, die per KI-Vektor-Suche in der Datenbank identifiziert wurden.
 Backup & Sicherheit
Backup & Sicherheit
Ein kritischer Punkt war das Backup. Da die Daten verteilt liegen, reicht ein Backup des PCs nicht aus.
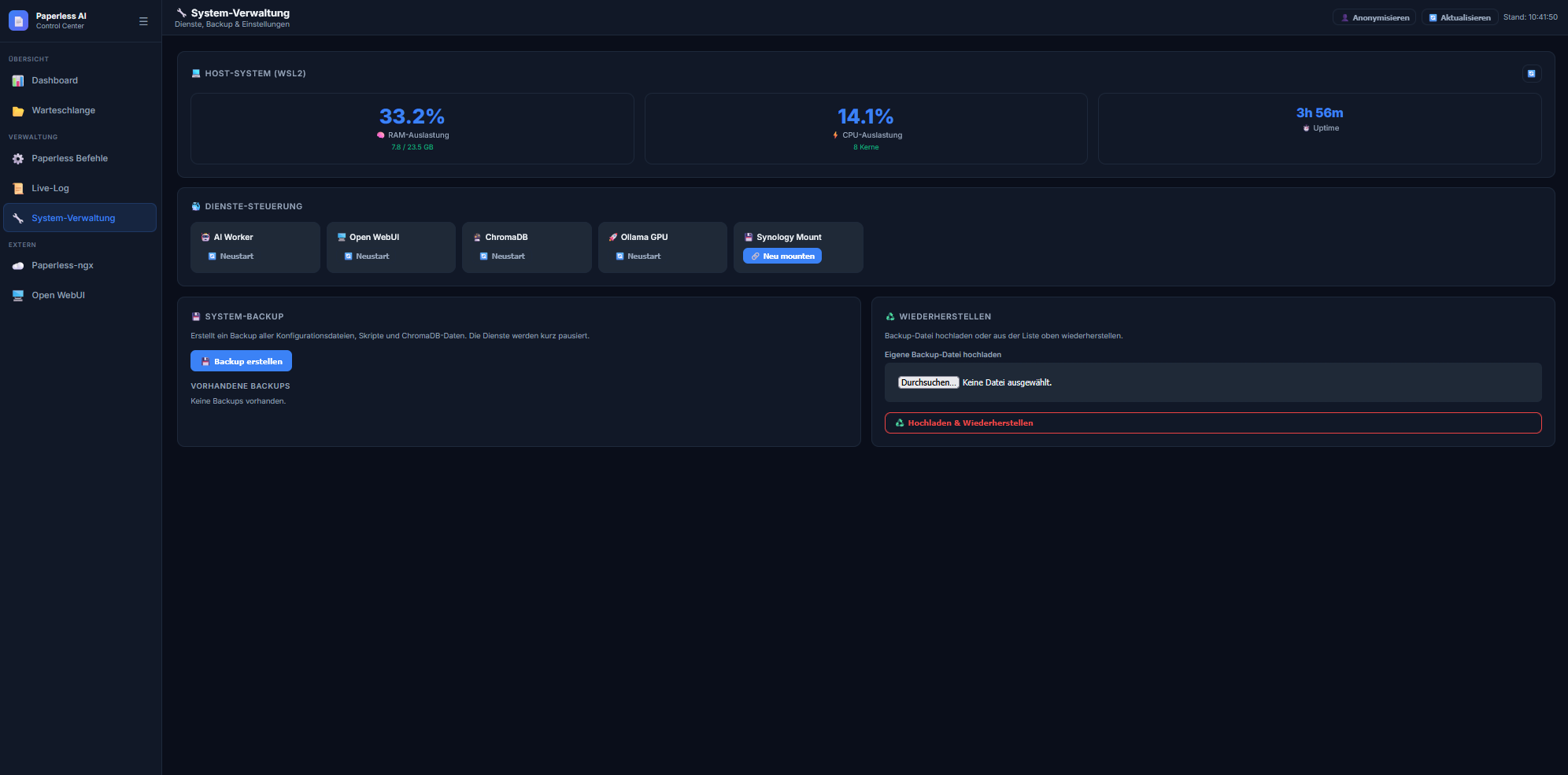
Zentrales Backup-Management
Das integrierte Backup-Skript erledigt nun folgendes mit einem Klick:
-
Erstellt einen PostgreSQL-Datenbank-Dump via SSH auf der Synology.
-
Sichert die Docker-Konfigurationen beider Systeme (PC & NAS).
-
Packt die KI-Vektordatenbank (ChromaDB) vom PC mit ein.
-
Speichert alles in einem zentralen, komprimierten Archiv auf der Workstation.
Technische Details
-
Frontend: HTML5/CSS3 (Vanilla), JavaScript mit Echtzeit-Polling.
-
Backend: Flask (Python) mit Docker-SDK und SSH-Integration.
-
Kommunikation: Direkter CIFS/SMB3-Mount zwischen WSL2 und Synology für maximale Dateiperformance.
Das Projekt hat die Wartung meines Paperless-Systems massiv vereinfacht, da ich nicht mehr zwischen DSM-Oberfläche, Portainer und Terminal-Sessions hin- und herspringen muss.
Interesse am Setup? Ich habe das gesamte Setup (Docker-Konfigurationen, Python-Skripte für den Watchdog und Sync-Logik) modular aufgebaut. Falls Interesse besteht, kann ich die Repo-Struktur gerne auf GitHub zur Verfügung stellen, damit ihr euch das mühsame Kleben der Einzelteile spart.
Was nutzt ihr für KI-Workflows in eurem Paperless? Ich freue mich auf den Austausch!
Viele Grüße, Heiko