Hallo Liebe Community,
ich habe mich nun fast 2 Wochen intensiv mit paperless ngx beschäftigt
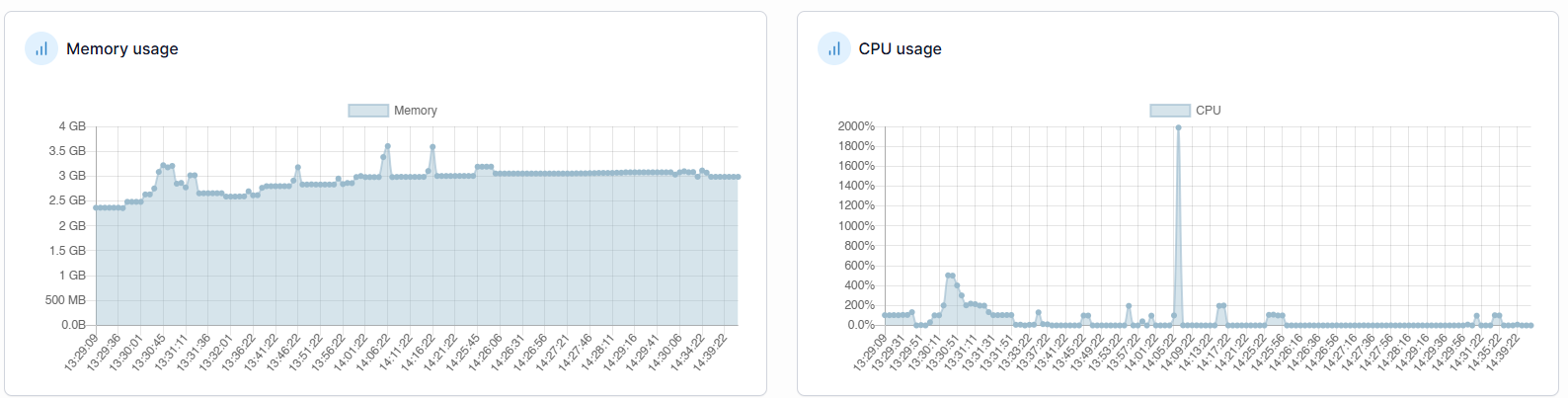
Meine beiden Instanzen laufen auf einer Debian 13 (Trixie) VM in Docker
10 CPU zugewiesen
16 GB RAM
NFS Mount => Synology
Problem:
Beim bearbeiten Bsp. Tags setzen Kontrolle..
PDF’s mit ungefähr 20 Seiten Text bzw. auch vereinzelt andere hängt sich Paperless auf.
WEB-GUI Zugriff nicht mehr möglich. Ich muss dann den gesamten Container neustarten.
NGNIX Proxy habe ich als Entlastung auch vorgeschaltet.
Ich finde so ist es leider kein Produktives System - und ich leider gerade unter Schlafmangel
PAPERLESS_OCR_MODE habe ich auch schon rumgespielt
Vielleicht habt Ihr einen Mega Tip für mich - da ecoDMS und andere teure Systeme eigentlich nicht in Frage kommen. Ich würde dann maximal nochmal zu mayan edms wechseln (anschauen) - aber dort habe ich nichts gefunden wegen XML (E-Rechnung) Verarbeitung. Dies habe ich mit Paperless ja schon hinbekommen.
Meine config von Paperless
pl_archiv_app:
container_name: pl-archiv-app
image: ghcr.io/paperless-ngx/paperless-ngx:latest
restart: unless-stopped
cpus: 10
mem_limit: 16g
depends_on:
postgres:
condition: service_healthy
redis:
condition: service_healthy
tika:
condition: service_healthy
gotenberg:
condition: service_healthy
environment:
PAPERLESS_DBHOST: postgres
PAPERLESS_DBPORT: "5432"
PAPERLESS_DBNAME: ${POSTGRES_DB_ARCHIV}
PAPERLESS_DBUSER: ${POSTGRES_USER_ARCHIV}
PAPERLESS_DBPASS: ${POSTGRES_PASSWORD}
PAPERLESS_DBENGINE: postgresql
PAPERLESS_ENABLE_FLOWER: "true"
PAPERLESS_REDIS: redis://redis:6379/0 # Archiv
PAPERLESS_REDIS_PREFIX: "archiv:"
PAPERLESS_REDIS_CACHE_TTL: "600"
PAPERLESS_TIME_ZONE: ${PAPERLESS_TIME_ZONE}
PAPERLESS_OCR_MODE: "skip"
PAPERLESS_OCR_LANGUAGES: ${PAPERLESS_OCR_LANGUAGES}
PAPERLESS_OCR_LANGUAGE: ${PAPERLESS_OCR_LANGUAGE}
PAPERLESS_OCR_ROTATE_PAGES: "true"
PAPERLESS_OCR_ROTATE_PAGES_THRESHOLD: "12"
PAPERLESS_OCR_OUTPUT_TYPE: "pdf"
# PAPERLESS_OCR_USER_ARGS: '{"language": "deu+eng","rotate_pages": true,"deskew": true,"clean": true,"optimize": 3,"fast_web_view": 1,"redo_ocr": true,"invalidate_digital_signatures": true}'
# PAPERLESS_OCR_USER_ARGS: '{"optimize": 1, "deskew": true, "fast_web_view": 1, "invalidate_digital_signatures": true}'
PAPERLESS_COOKIE_PREFIX: plx1
PAPERLESS_ALLOWED_HOSTS: "x.x.x.x,localhost,127.0.0.1"
# Worker/Threads
PAPERLESS_WORKER_TIMEOUT: "5400"
PAPERLESS_WEBSERVER_WORKERS: "5"
PAPERLESS_THREADS_PER_WORKER: "2"
PAPERLESS_TASK_WORKERS: "2"
# Filename und Ort der Datei
PAPERLESS_FILENAME_FORMAT: "inbox/{{ created_year }}/{{ title|slugify }}"
USERMAP_UID: ${USERMAP_UID}
USERMAP_GID: ${USERMAP_GID}
PAPERLESS_CONSUME_DIR: /usr/src/paperless/consume
PAPERLESS_MEDIA_ROOT: /usr/src/paperless/media
PAPERLESS_EXPORT_DIR: /usr/src/paperless/export
PAPERLESS_EMPTY_TRASH_DIR: /usr/src/paperless/media/trash
XML_ARCHIV_DIR: /usr/src/paperless/media/xml-archiv
# Tika/Gotenberg Endpoints
PAPERLESS_TIKA_ENABLED: ${PAPERLESS_TIKA_ENABLED}
PAPERLESS_TIKA_ENDPOINT: ${PAPERLESS_TIKA_ENDPOINT}
PAPERLESS_TIKA_GOTENBERG_ENDPOINT: ${PAPERLESS_TIKA_GOTENBERG_ENDPOINT}
# LOG Managment
PAPERLESS_LOGROTATE_MAX_SIZE: ${PAPERLESS_LOGROTATE_MAX_SIZE}
PAPERLESS_LOGROTATE_MAX_BACKUPS: ${PAPERLESS_LOGROTATE_MAX_BACKUPS}
PAPERLESS_CONSUMER_POLLING: "10" # alle 10s nach neuen Dateien suchen
PAPERLESS_CONSUMER_IGNORE_PATTERNS: '["\\.xml$"]'
# PAPERLESS_CONSUMER_DISABLE: "false"
PAPERLESS_CONSUMER_DELETE_DUPLICATES: "true"
PAPERLESS_CONSUMER_RECURSIVE: "true" # falls du Unterordner im consume nutzt
# zum Debuggen:
# PAPERLESS_LOGLEVEL: "DEBUG"
volumes:
- /srv/paperless/archiv/nas/archiv/consume:/usr/src/paperless/consume
- /srv/paperless/archiv/nas/archiv/media:/usr/src/paperless/media
- /srv/paperless/archiv/nas/archiv/export:/usr/src/paperless/export
- /srv/paperless/archiv/data:/usr/src/paperless/data
- /srv/paperless/archiv/scripts:/scripts:ro
- /srv/paperless/archiv/addons:/addons:ro
tmpfs:
- /tmp:size=1G
labels:
- "paperless.container=webserver"
# ports:
# - "8080:8000"
networks:
- paperless_frontend
- paperless_backend
Vielen Lieben Dank im Vorraus ![]()