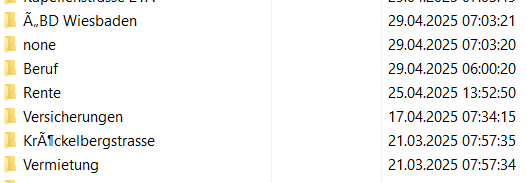Ich habe mich anscheinend unklar ausgedrückt:
Das Problem scheint nicht die Texterkennung selbst oder PDF erstellung zu sein- Dort sind die Umlaute korrekt.
Es geht um die Speicherpfade
Ich verwende 2.15.3 und alles ist auf deutsch eingestellt.
Ich füge mal einen Screenshot bei.
Die verkrüppelten sollten „ÄBD“ und „Kröckelbergstrasse“ sein
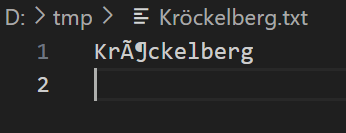
Das sieht nach unterschiedlichen Encodings aus. Genauer: Paperless legt die Dateinamen in UTF-8 an und das Directory-Listing ist Windows-1252 oder ähnlich.
Ich habe hier mal im Texteditor Kröckelberg mit UTF-8 Encoding gespeicher und mit Windows-1252 Encoding geöffnet.
Okay. Das klingt logisch
Der Screenshot ist mit winSCP gemacht worden.
Ich muss jetzt mal rausfinden ob das vielleicht nur Problem des Zugriffs über SCP ist