ich bin sehr angetan von Paperless. Es läuft auf einer Synology, als Scanner kommen ein MFC-9670 und ein ADS-4900 zum Einsatz.
Per Zufall habe ich entdeckt, dass Postgres als Prozess nicht mehr zu starten ist. Der Prozess ist dauerhaft gestoppt. Version 16 ist installiert. Alle anderen Prozesse laufen ohne Fehlermeldungen seit geraumer Zeit. Bemerkbar macht sich das nicht. Ich kann scannen, die Dokumente kommen an. Grundsätzlich kann ich also arbeiten.
Es gibt Backups, allerdings würde ich mit dem Einspielen auch diverse bereits gescannte Dokumente verlieren. Außerdem kann ich zeitlich nicht eingrenzen, wann der Fehler erstmals aufgetreten ist. Dennoch möchte ich den Fehler gerne beheben. Da ich an meiner IT einige andere Dinge ändere, möchte ich Paperless noch einmal komplett neu aufsetzen. Die Hardware-Basis bleibt aber unverändert.
Nun habe ich folgenden Gedankengang: Die rund 300 bereits erfassten Dokumente habe ich in der Dateiablage von Paperless als Originale vorliegen. Diese möchte ich sichern, den Rest der Installation danach löschen. Dann setze ich Paperless nach den Vorgaben der Master-Class wieder neu auf. Die gesicherten Dokumente lese ich dann neu ein, was ja per Drag & Drop hervorragend funktioniert.
Bevor ich das mache: Habe ich da irgendwo einen Denkfehler? Oder funktioniert mein Ansatz grundsätzlich? Dass mit Konfigurationseinstellungen verloren gehen, ist mir bewusst. Das ist aber kein großes Ding, da ich aktuell mehr im Sammel-, denn im Auswertemodus unterwegs bin. Vielleicht ist die Frage zu einfach. Die rund 300 Dokumente sind mir allerdings wichtig. Deswegen frage ich lieber vorher einmal.
dein Ansatz ist im Kern richtig: Die Originale solltest du im entsprechenden Ordner von Paperless finden. Wenn du dir unsicher bist, sichere am besten den kompletten Paperless-Ordner und ziehe dir anschließend die Dokumente daraus heraus.
Vom Hochladen aller 300 Dokumente per Drag & Drop würde ich eher abraten. Es funktioniert zwar, kann aber je nach Dateigröße sehr lange dauern und ist mühsam. Sinnvoller ist es, Paperless neu zu installieren und die gesicherten Dokumente in den consume-Ordner zu legen. Dann kann Paperless alles im Hintergrund automatisch verarbeiten, während dein Rechner nicht laufen muss – das ist deutlich performanter und stabiler.
posgtgres läuft doch in einem anderen Container, oder? Könnte es sein, dass Du nur den EINDRUCK hast postgres liefe nicht, da Du nicht im richtigen ontainer nachscaust?
Ich wollte vor kurzem ein Backup der postgres-DB anstossen; pg_dump schlägt von der Kommandozeile fehl; erst im postgres-Container selber geht es.
…manchmal sieht man ja den Wald vor lauter Bäumen nicht.
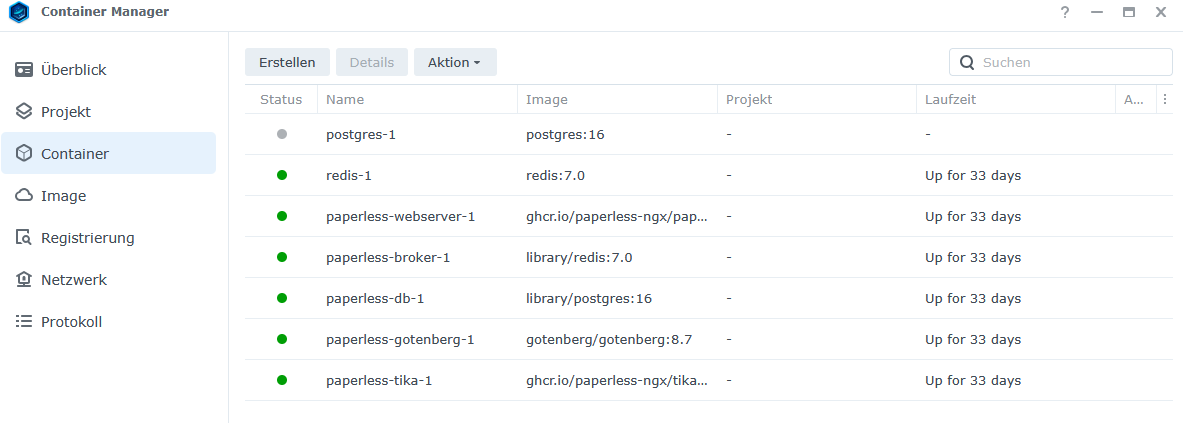
Mir ist jetzt erst aufgefallen, dass es den Container “paperless-db-1” gibt. Dahinter taucht der Begriff “postgres 16” auf. Dieser Container läuft, so wie alle anderen auch, seit über 30 Tagen. Die 30 Tage kommen von einem Herunterfahren des NAS, sonst stünde dort eine längere Zeitspanne. Ist das der eigentliche Datenbank-Container?
Wenn dem so sein sollte, ist der Container, der im Screenshot mit grauem Punkt dargestellt wird, überhaupt notwendig? Ich kann nicht sagen, wo der herkommt. Ich bin mir ehrlich gesagt auch nicht sicher, ob der schon immer da war. Kann ich den löschen? Laufen tut er nicht und scannen kann ich. Habe ich gerade noch einmal ausprobiert.