OliverH
20. September 2024 um 13:53
1
Ich habe eine große Menge an PDF-Rechnungen mit bestehendem Text-Layer, die ich in paperless importieren möchte.
Ich habe in docker-compose.env den entsprechenden Parameter bewusst auf „skip“ gesetzt um die bestehenden Text-Layer nicht zu verändern.
Bei etwa 10% der Dokumente „beschädigt“ paperless aber den Textlayer:
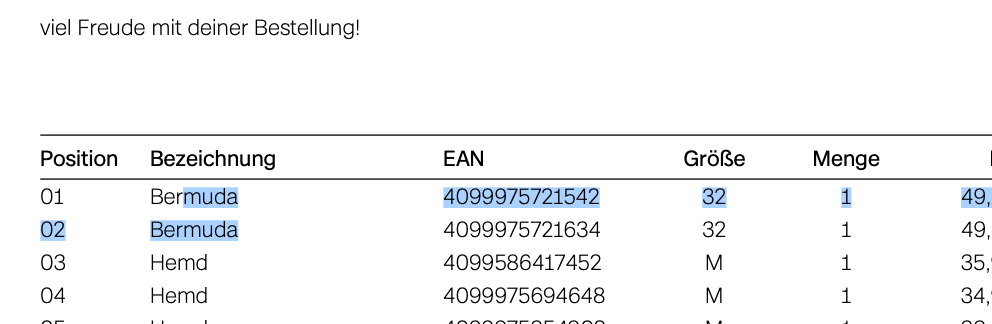
Vor der Verarbeitung war es z.B. in dieser Rechnung möglich einzelne Worte zu markieren:
Damit konnte man auch im Mac Finder nach einzelnen Worten (zB. Bermuda) suchen.
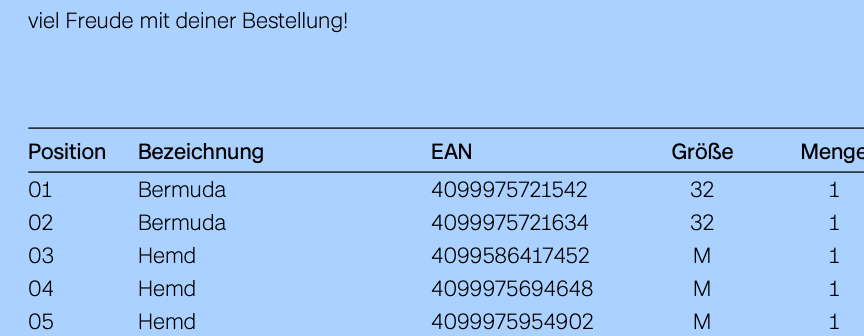
Nach der Verarbeitung findet die Mac Finder Suche keine Inhalte der Rechnung mehr und es können auch keine einzelnen Worte mit der Maus im PDF-Dokument markiert werden:
Weiß jmd. dazu eine Lösung?
Besten Dank im Voraus.
Oliver
OliverH
20. September 2024 um 16:02
2
Nach einigem Testen sieht es so aus als würde paperless trotz des Parameters
PAPERLESS_OCR_MODE=skip
bei pdfs mit Textlayer einen neuerlichen OCR-Durchlauf starten wenn folgender Parameter gesetzt ist …
PAPERLESS_OCR_SKIP_ARCHIVE_FILE=never
… anstatt einfach das Original ins Archiv zu übernehmen. Und dabei wird leider der ein oder andere Textlayer beschädigt.
Ich bin diesbezüglich eigentlich den Empfehlungen aus dem Videokurs: Paperless-ngx mit Synology Drive synchronisieren gefolgt.
Meines Erachtens wäre entgegen den Empfehlungen des Kurses aber der bessere Weg die Parameter wie folgt zu setzen …
PAPERLESS_OCR_MODE=skip
PAPERLESS_OCR_SKIP_ARCHIVE_FILE=with_text
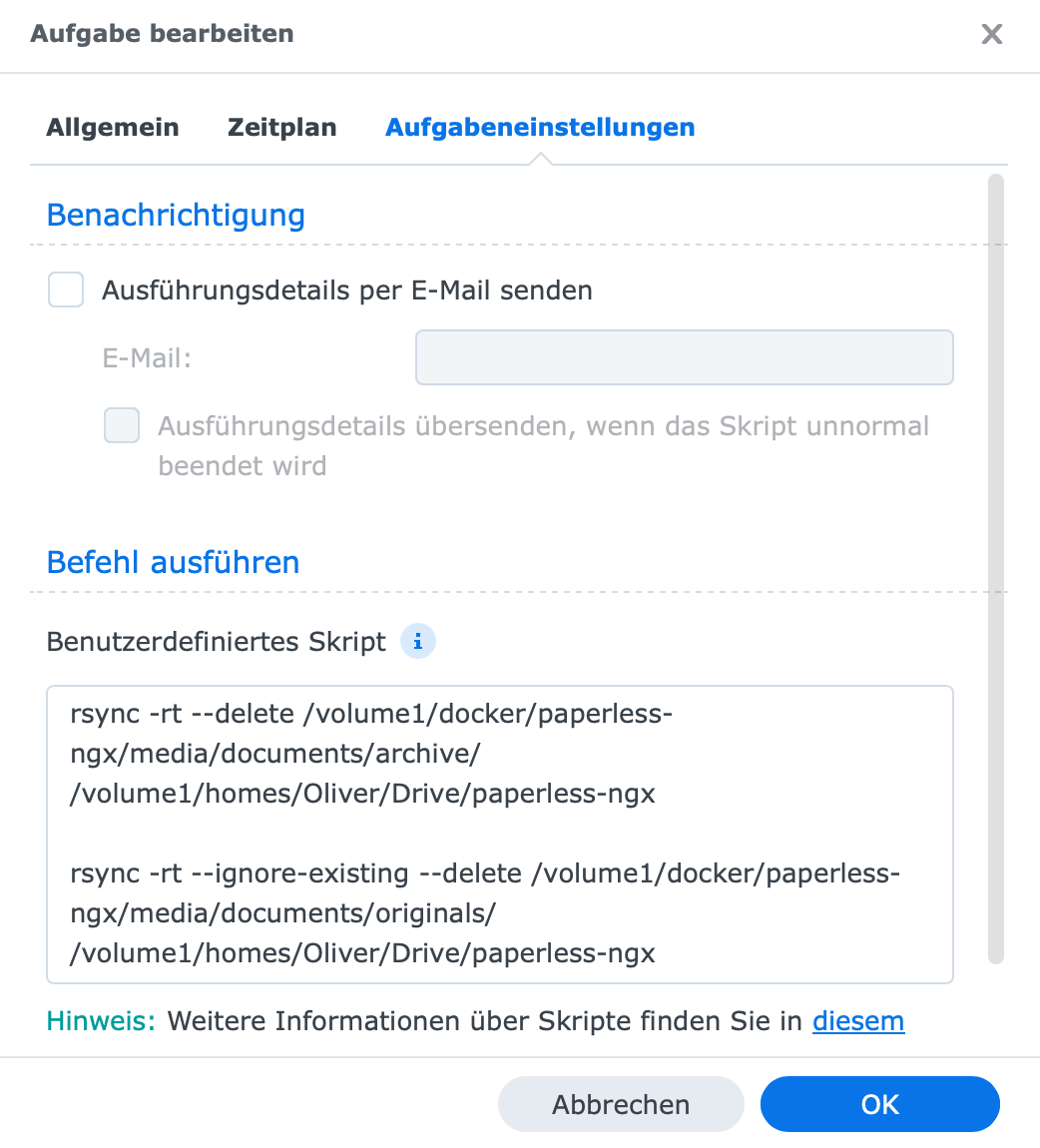
… und die Synchronisierung nach Synology Drive mit folgendem (im vorigen Post angeführten) Skript zu bewerkstelligen:
Das hat folgende Vorteile:
keine Duplikate im folder „archive“
kein neuerliches OCR, wenn nicht nötig
und dadurch geringeres Risiko, das bestehende Textlayer beschädigt werden.
@Stefan : Vielleicht willst du im Videokurs zur Synology Drive darauf hinweisen.
Stefan
21. September 2024 um 05:50
3
Herzlichen Dank für den Hinweis, ich vermute, dass hier in einem der letzten Updates etwas an der Logik geändert wurde. Ich habe es aufgenommen und werde es nach genauer Prüfung in den Kurs mit aufnehmen.
Top Arbeit, danke @OliverH !