Hallo,
habe paperless ngx auf unserer Synology DS auf Docker installiert.
Klappt mit den ausprobierten Doks soweit gut.
Um einen für uns zu Hause sinnvollen, automatisierten und benutzerbezogenen Workflow zu generieren, sollte jeder User einen eigenen Eingangs- (consume) und Ausgangs-Ordner (achive) bekommen. Speichernamen/Pfad sollen automatisiert vergeben werden, Tags/ Dokumenttyp sollen auch vom System gelernt werden, also am besten gar kein händisches Eingreifen über die Web-UI.
Also z.b. ich packe via Windows Explorer ein Dok. in „meinen“ consume-Ordner, es wird verarbeitet und in „meinen“ Ausgabeordner gespeichert.
Beim Scannen ließe sich das auch einfach lösen, in dem die Benutzer eben auch in ihre persönlichen Ordner scannen.
sollte mit ein paar Umwegen gehen.
Teilen wir das ganze Mal in zwei Teilprobleme auf.
Einzelne Consume-Ordner pro Benutzer
Einzelne Archive-Ordner pro Benutzer
Beides geht gut, aber nur mit der Begrenzung, dass alle Benutzerordner (sowohl Archive als auch Consume) auf der selben Ebene als Kindelement eines übergeordneten Archive- oder Consume-Ordners sein müssen. Heißt im Klartext: Man kann nicht einen Benutzerordner auf ein NAS legen, den anderen lokal, usw…
Das kann man dann nur mit Trickserei und symbolischen Links erreichen.
Einzelne Consume-Ordner pro Benutzer
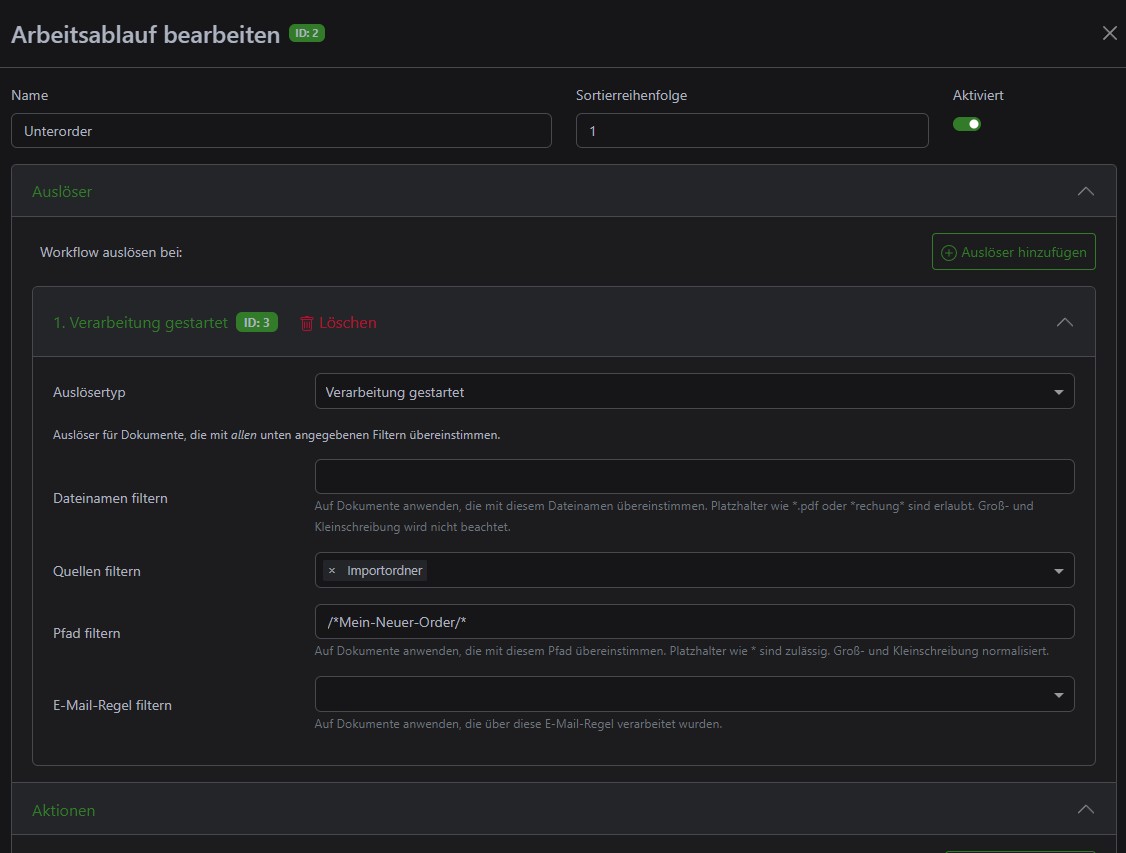
Paperless-ngx kann mit der Option PAPERLESS_CONSUMER_SUBDIRS_AS_TAGS (in Verbindung mit PAPERLESS_CONSUMER_RECURSIVE) Tags aus Unterordnern im Consume-Verzeichnis erstellen. Packe ich also eine Datei in einen Unterordner mit dem Gesamtpfad „consume/subst-user1/test.pdf“, erstellt Paperless daraus eine Datei test.pdf mit dem Tag „subst-user1“. Das geht leider nur mit Tags, nicht mit Dokumententypen oder Besitzern. ABER: Über die „Arbeitsabläufe“ in der Web UI kann man einen Ablauf bauen, der nach dem Hinzufügen eines Dokuments aktiv wird und einen Pseudo-Tag durch einen neuen Besitzer ersetzt. So ein Workflow muss zwar für jeden Benutzer mit Unterordner erstellt werden, aber bei ein paar Leuten ist das recht überschaubar. Der Workflow sieht dann ungefähr wie folgt aus:
Auslöser:
– Dokument hinzugefügt
— mit Tag „subst-user1“
Die Pseudo-Tags würde ich alle nach dem gleichen Schema benennen und vor allen Nicht-Administrativen Nutzern verstecken. Dann läuft die Ersetzung völlig unsichtbar für den User ab.
Einzelne Archive-Ordner pro Benutzer
Das ist eigentlich recht simpel. Über PAPERLESS_FILENAME_FORMAT fügt man ganz am Anfang ein {owner_username}/ hinzu. Dann sortiert Paperless automatisch alle Dokumente in die entsprechenden User-Ordner ein.
Nachdem das alles so konfiguriert wurde, kann man natürlich die User-Ordner separat freigeben und mit entsprechenden Zugriffsrechten nur für die jeweiligen Nutzer versehen, falls notwendig. Dabei aber nicht ausversehen Paperless den Zugriff entziehen.
Ich nutze diese Methode, um Belege automatisch bei der Consumption einem Dokumententyp zuzuordnen.
Vielleicht ist es noch einfacher, eine weitere, komplett eigenständige Instanz zu erstellen. Dann sind auch die Dokumente in der Browseransicht sauber getrennt.
Gibt es dafür eine Anleitung für Synology / Docker? Müssen dann redis, postgres und paperless-ngx jeweils ein zweites Mal installiert werden?
Das geht nur, wenn du auch Kriterien hast, die PLNGX auch auswerten kann. Das hat ein Dokument in der Regel aber nicht, und wenn ich das richtig sehe, ist der owner auch nicht im classifier drin.
Dann bleibt die halt nichts anderes übrig, als solch ein Kriterium „künstlich“ hinzuzufügen.
Moin @FuXXz
ich antworte hier auf ein etwas älteres Thema, ich stehe aber genau vor dem gleichen Problem, dass ich eigentlich Dokumente für mich, meine Frau und die beiden Kinder ablegen will. Damit der WAF stimmt, sollten Dokumente am Scanner die mit der Schnellwahltaste meiner Frau gescannt werden, dann auch direkt ihr Tag bekommen. Dokumente mit der Schnellwahltaste Kinder –> Kinder und Dokumente mit der Schnellwahltaste Moritz –> Moritz.
Nur: Paperless NGX komsumiert bei mir keine Unterordner im “consume” ordner. Sprich: Wenn ich da einen Unterordner “kinder” anlege, dann kann beginn er mit der Verarbeitung gar nicht.
Der Weg über einen Identifier im Dateinamen geht auch nicht, da der Brother ADS 1700W keine Dateinamen je Schnellwahltaste / Profil zulässt.
Danke. Ich habe tatsächlich nun einmal eine neue Paperless NGX Instanz neben meiner bestehenden Instanz aufgebaut. Mit der neuen Instanz bekomme ich es sauber zum Laufen, mit der alten Instanz nicht.
Meine bisherige Instanz war bzw. ist auf der Version 2.13.5, die neue Instanz ist auf der aktuellen Version 2.20.6.
Nun hatte ich die Hoffnung, dass ich per Document_Exporter und Document_Importer alle Dokumente umziehen kann - das schlägt leider fehl.
Ich glaube Ursache sind auch die beiden unterschiedlichen PostGres Varianten (Postgres 13 vs. Postgres 18).
Die paperless Version muss beim Import die selbe sein wie beim Export.
Ich würde dein aktuelles Paperless so hoch ziehen von der Version wie möglich. Bitte genau lesen in den den Versions Hinweisn. Dann ein Export machen und dann ein Import mit der selben Paperless Version und einer PostgreSQL Version 17 oder 18. Bei der 18er muss der data Pfad aber angepasst werden. Aber dazu findet man alle Infos hier im Forum.