Hallo, in den Dateiaufgaben habe ich gesehen, dass der Import einiger Dokumente mit der Fehlermeldung Besondere Versicherungsbedingungen.pdf: Error occurred while consuming document Besondere Versicherungsbedingungen.pdf: SubprocessOutputError: Ghostscript PDF/A rendering failed. See logs for more information. gebrochen hat.
Es handelte sich dabei um Versicherungsbedingungen und um Kontoauszüge.
2016-03-01 Bezuegemitteilung.pdf: Error occurred while consuming document 2016-03-01 Bezuegemitteilung.pdf: SubprocessOutputError: Ghostscript PDF/A rendering failed. See logs for more information.
Ist nur eins von 200 Dokumenten. Auch wiederholtes Hochladen ändert nichts…
Also mein PDF war nicht passwortgeschützt. Kam vom selben Ersteller wie 170 andere Dokumente, die problemlos verarbeitet wurden. Was der andere Thomas für ein Dokument hatte, weiß ich nicht…
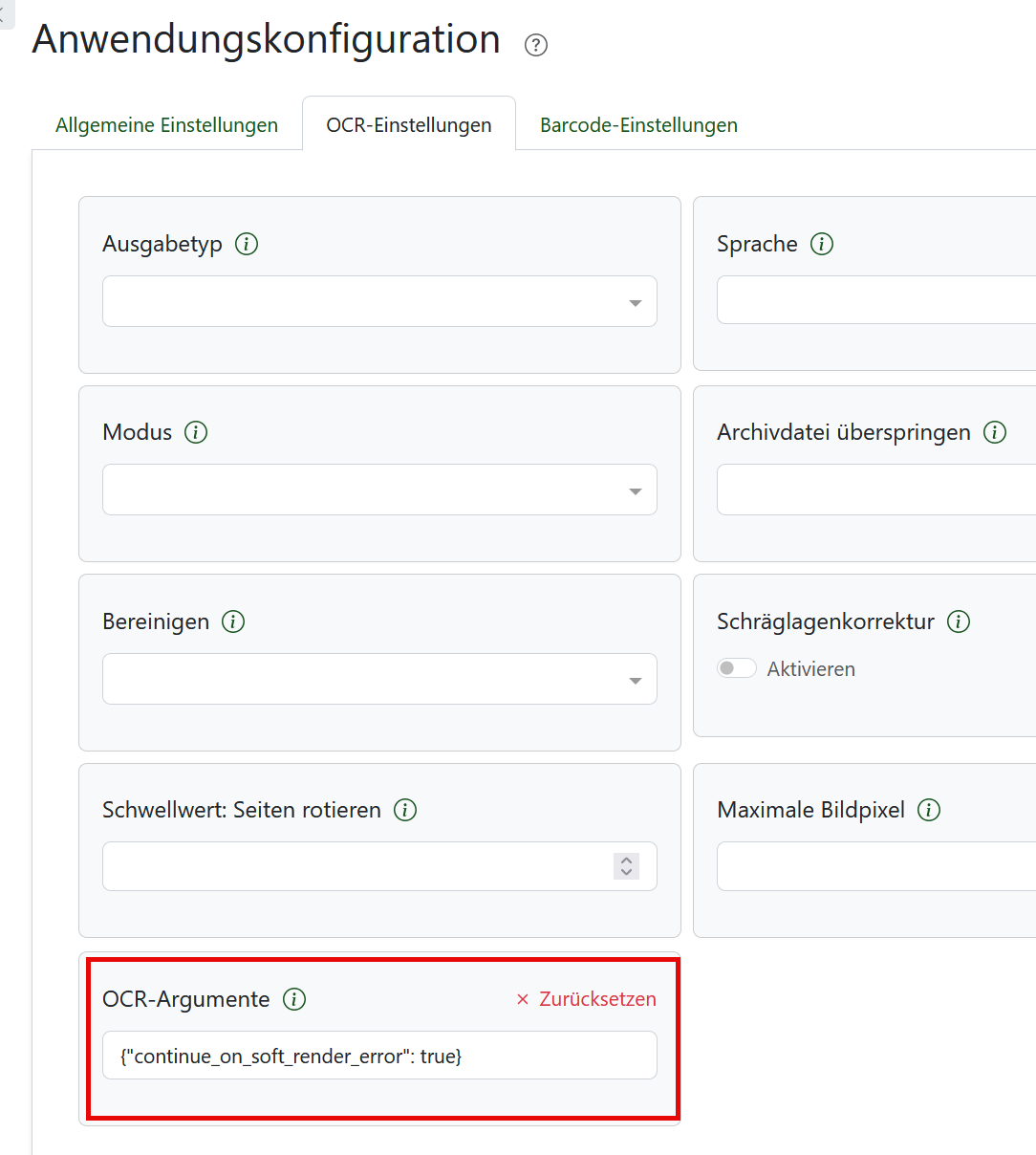
über das Bild-Symbol lässt sich leider kein pdf anhängen. Ich habe in diesem Zusammenhang mal weitergemogelt und bin auf folgende Aussage gestoßen:
Blockzitat Consumption fails with „Ghostscript PDF/A rendering failed“
Newer versions of OCRmyPDF will fail if it encounters errors during processing. This is intentional as the output archive file may differ in unexpected or undesired ways from the original. As the logs indicate, if you encounter this error you can set PAPERLESS_OCR_USER_ARGS: ‚{„continue_on_soft_render_error“: true}‘ to try to ‚force‘ processing documents with this issue.'` to try to ‚force‘ processing documents with this issue.
Ich habe dann mal das PAPERLESS_OCR_USER_ARGS: '{„continue_on_soft_render_error“: true} in die docker-compose.yml eingefügt. Dann gab es jedoch eine Fehlermeldung bei runterfahren des Containers:(root) Additional property PAPERLESS_OCR_USER_ARGS is not allowed
Ich sattel mich mal auf. Habe genau das selbe Problem
SubprocessOutputError: Ghostscript PDF/A rendering failed. See logs for more information.
Bei mir ist es ein Handbuch. Kein Passwortgeschütztes Dokument. Es ist allerdings 11 MB groß. Das selbe Problem tritt auch bei einem andere PDF mit 88 MB. Alle anderen >900 Dokumente gingen durch.
Könnte es daran liegen, dass das Dokument einfach zu viel MB hat?
Ich habe bei mir die PAPERLESS_OCR_USER_ARGS wie folgt gesetzt: {"invalidate_digital_signatures": true,"continue_on_soft_render_error": true}
Der erste Wert ist für signierte PDFs, der 2. hat solche Fehler wie hier beschrieben verhindert.
Ich habe bei mir jetzt fast 9000 Dokumente drin und die größten haben knapp 300MB - also an der Größe liegt es wahrscheinlich nicht.
Ich meine aber, dass ich schon mal gesehen habe, dass es einen Fehler gibt, wenn das Rendern zu lange dauert.
Ich hole diesen Topic nochmal hoch. Bin gerade dabei Paperless zu testen ob es geeignet ist mein altes DMS abzulösen. Beim Import bekomme ich auch diesen Fehler. (Pdf im Anhang).
Entsprechend dem Vorschlag in der Doku habe ich dises Argument gesetzt. Nützt aber nichts.