Hallo zusammen!
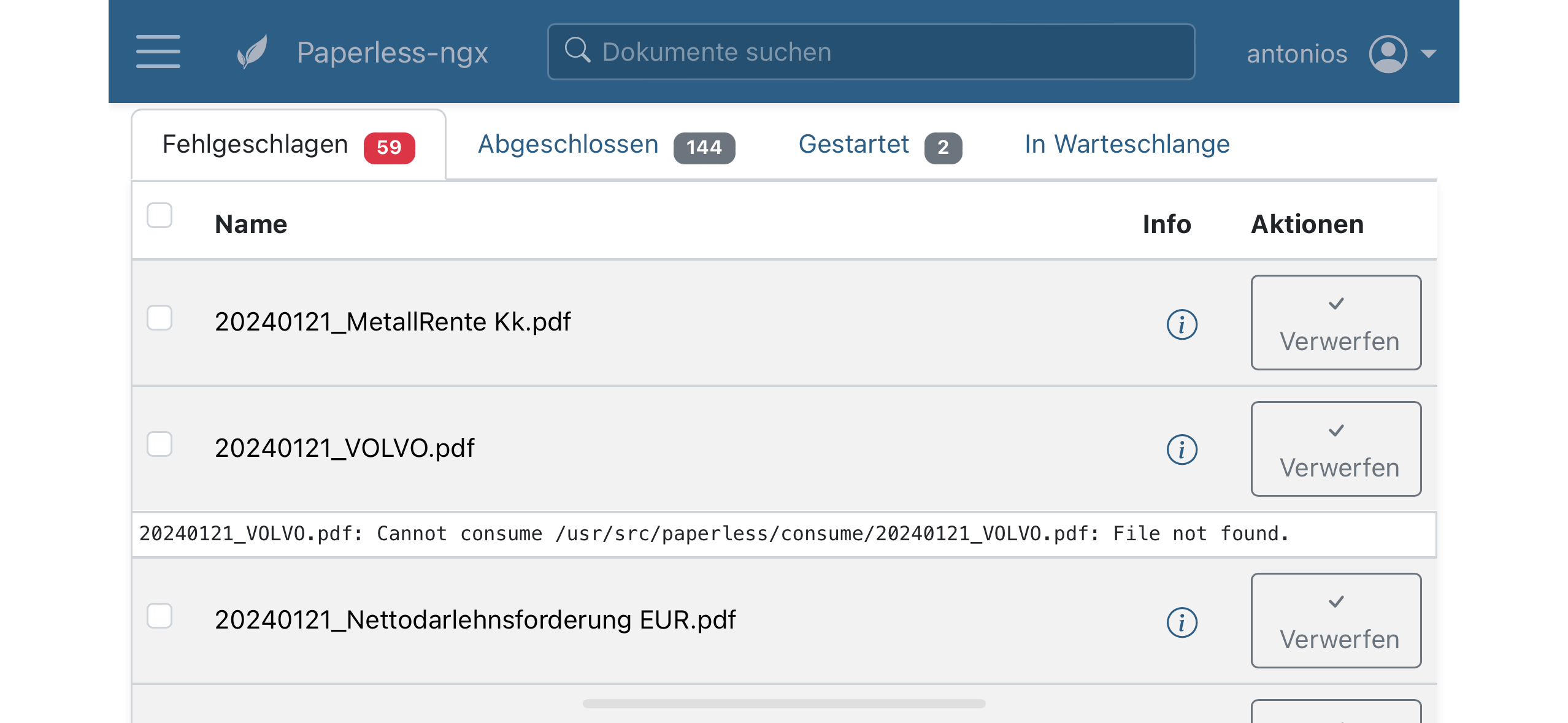
im Folgenden der Auszug aus dem Protokoll, interessanterweise ist die Datei konsumiert worden und findet sich in der Datenbank. Werde das jetzt noch sicherheitshalber für alle Dateien prüfen. Schade das gibt nicht wirklich Sicherheit, wenn man viele Dateien hintereinander scannt und Papiere in Richtung Papierkorb legt.
[2024-01-22 00:47:57,318] [INFO] [paperless.consumer] Consuming 20240121_MetallRente Kk.pdf
[2024-01-22 00:47:57,328] [DEBUG] [paperless.consumer] Detected mime type: application/pdf
[2024-01-22 00:47:57,343] [DEBUG] [paperless.consumer] Parser: RasterisedDocumentParser
[2024-01-22 00:47:57,352] [DEBUG] [paperless.consumer] Parsing 20240121_MetallRente Kk.pdf…
[2024-01-22 00:47:58,205] [DEBUG] [paperless.parsing.tesseract] Calling OCRmyPDF with args: {‚input_file‘: PosixPath(‚/tmp/paperless/paperless-ngxtn4ircw4/20240121_MetallRente Kk.pdf‘), ‚output_file‘: PosixPath(‚/tmp/paperless/paperless-ypvc00wt/archive.pdf‘), ‚use_threads‘: True, ‚jobs‘: 4, ‚language‘: ‚deu‘, ‚output_type‘: ‚pdfa‘, ‚progress_bar‘: False, ‚color_conversion_strategy‘: ‚RGB‘, ‚skip_text‘: True, ‚clean‘: True, ‚deskew‘: True, ‚rotate_pages‘: True, ‚rotate_pages_threshold‘: 12.0, ‚sidecar‘: PosixPath(‚/tmp/paperless/paperless-ypvc00wt/sidecar.txt‘)}
[2024-01-22 00:50:48,306] [DEBUG] [paperless.parsing.tesseract] Incomplete sidecar file: discarding.
[2024-01-22 00:50:48,943] [DEBUG] [paperless.consumer] Generating thumbnail for 20240121_MetallRente Kk.pdf…
[2024-01-22 00:50:48,954] [DEBUG] [paperless.parsing] Execute: convert -density 300 -scale 500x5000> -alpha remove -strip -auto-orient /tmp/paperless/paperless-ypvc00wt/archive.pdf[0] /tmp/paperless/paperless-ypvc00wt/convert.webp
[2024-01-22 00:51:02,396] [DEBUG] [paperless.classifier] Document classification model does not exist (yet), not performing automatic matching.
[2024-01-22 00:51:02,405] [DEBUG] [paperless.consumer] Saving record to database
[2024-01-22 00:51:02,406] [DEBUG] [paperless.consumer] Creation date from parse_date: 2023-05-01 00:00:00+02:00
[2024-01-22 00:51:02,884] [DEBUG] [paperless.consumer] Deleting file /tmp/paperless/paperless-ngxtn4ircw4/20240121_MetallRente Kk.pdf
[2024-01-22 00:51:02,950] [DEBUG] [paperless.parsing.tesseract] Deleting directory /tmp/paperless/paperless-ypvc00wt
[2024-01-22 00:51:02,954] [INFO] [paperless.consumer] Document 2023-05-01 20240121_MetallRente Kk consumption finished
[2024-01-22 00:51:03,646] [DEBUG] [paperless.tasks] Skipping plugin CollatePlugin
[2024-01-22 00:51:03,647] [DEBUG] [paperless.tasks] Executing plugin BarcodePlugin
[2024-01-22 00:51:03,649] [DEBUG] [paperless.barcodes] Scanning for barcodes using PYZBAR
[2024-01-22 00:51:03,669] [WARNING] [paperless.barcodes] File is likely password protected, not checking for barcodes: Unable to get page count.
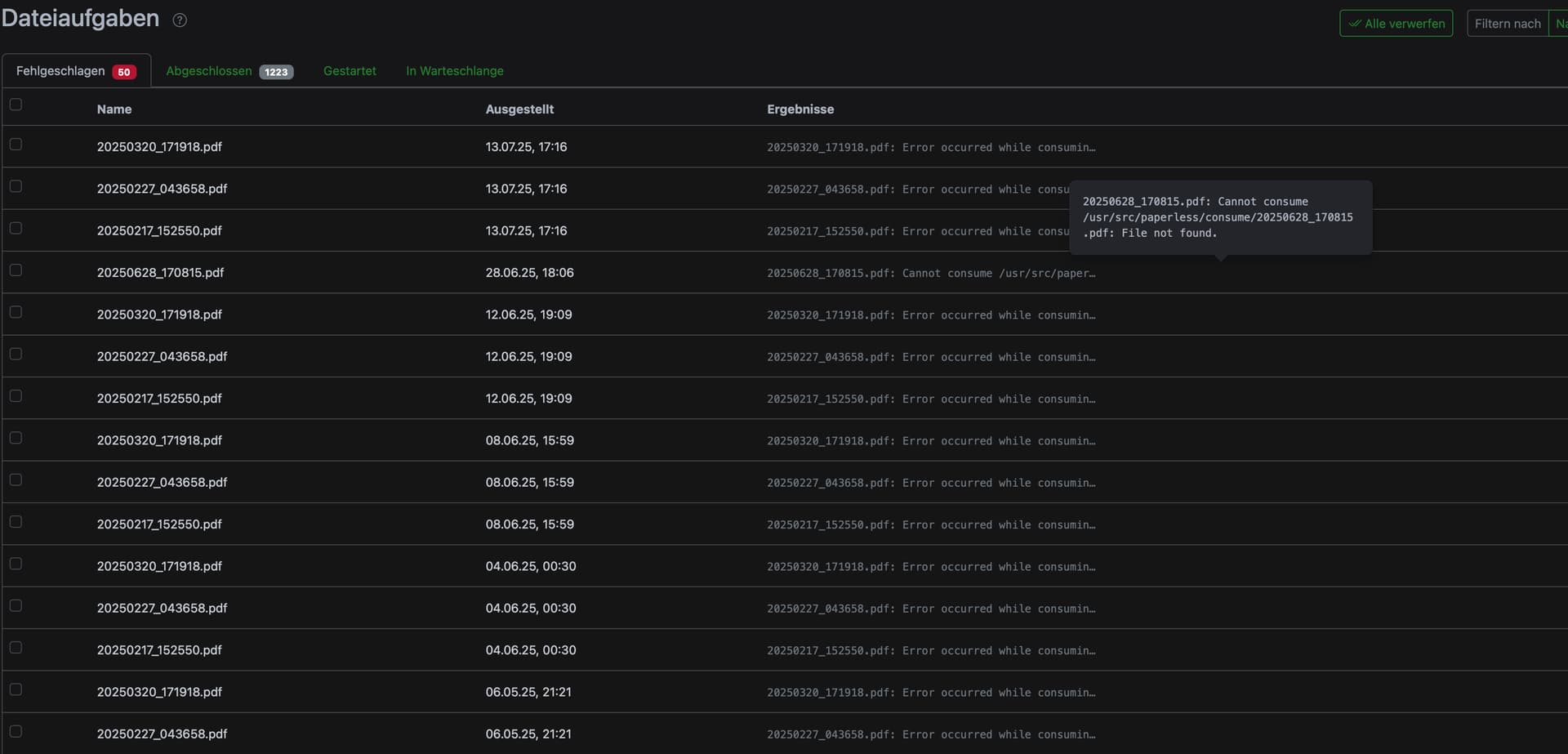
I/O Error: Couldn’t open file ‚/usr/src/paperless/consume/20240121_MetallRente Kk.pdf‘: No such file or directory.
[2024-01-22 00:51:03,671] [DEBUG] [paperless.barcodes] Scanning for barcodes using PYZBAR
[2024-01-22 00:51:03,691] [WARNING] [paperless.barcodes] File is likely password protected, not checking for barcodes: Unable to get page count.
I/O Error: Couldn’t open file ‚/usr/src/paperless/consume/20240121_MetallRente Kk.pdf‘: No such file or directory.
[2024-01-22 00:51:03,692] [INFO] [paperless.tasks] BarcodePlugin completed with: No pages to split on!
[2024-01-22 00:51:03,694] [DEBUG] [paperless.tasks] Executing plugin WorkflowTriggerPlugin
[2024-01-22 00:51:03,700] [INFO] [paperless.tasks] WorkflowTriggerPlugin completed with no message
[2024-01-22 00:51:03,725] [ERROR] [paperless.consumer] Cannot consume /usr/src/paperless/consume/20240121_MetallRente Kk.pdf: File not found.