Hallo
Ich weiß, das ist nicht die originäre Aufgabe von Paperless, aber ist es irgendwie möglich eine Datei in Paperless zu bearbeiten - z.B einen Vermerk „genehmigt“ oder gar eine digitale Unterschrift einzufügen?
Du kannst Vermerke als Kommentare einfügen:
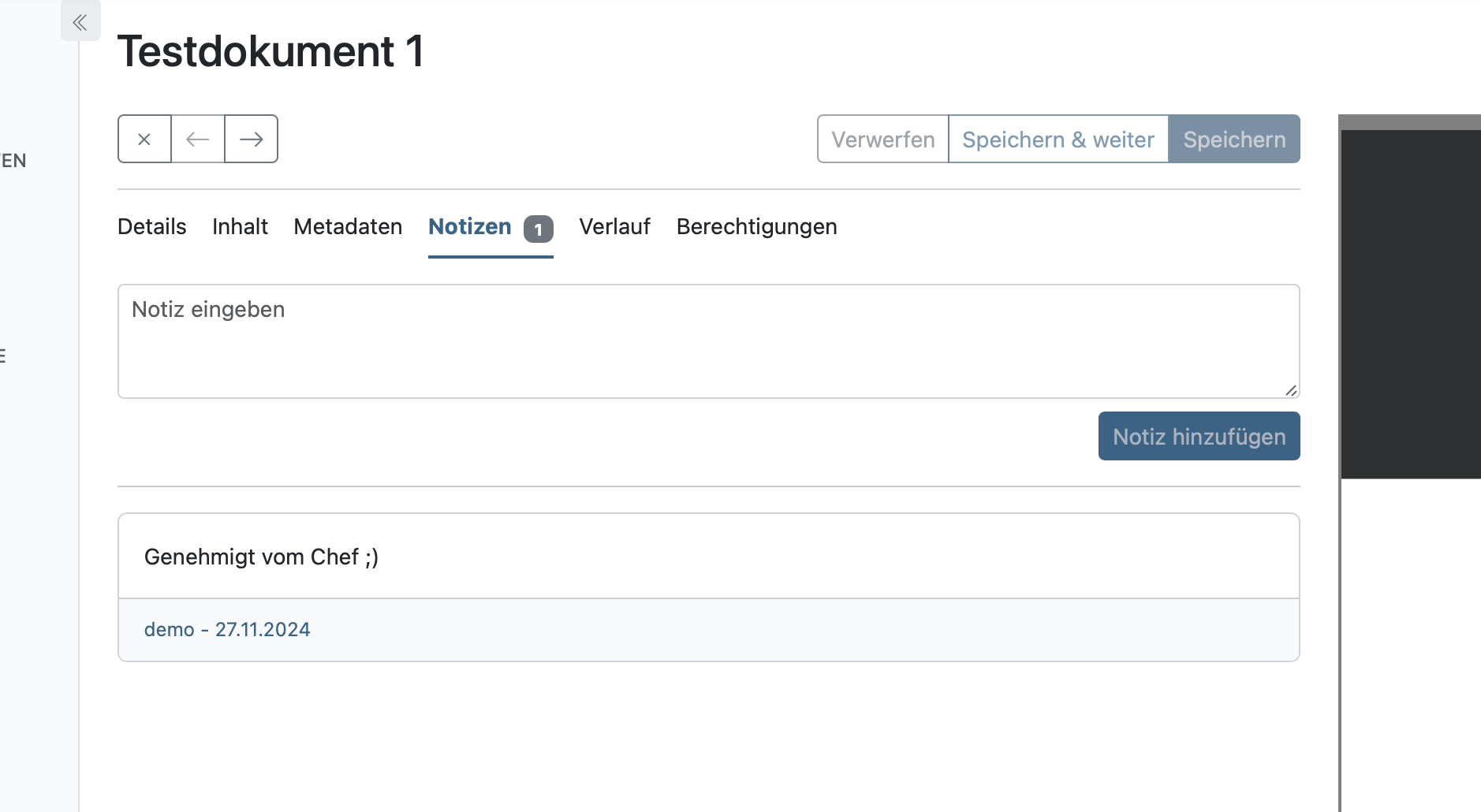
Alternativ kannst du auch Tags oder benutzerdefinierte Felder vergeben:
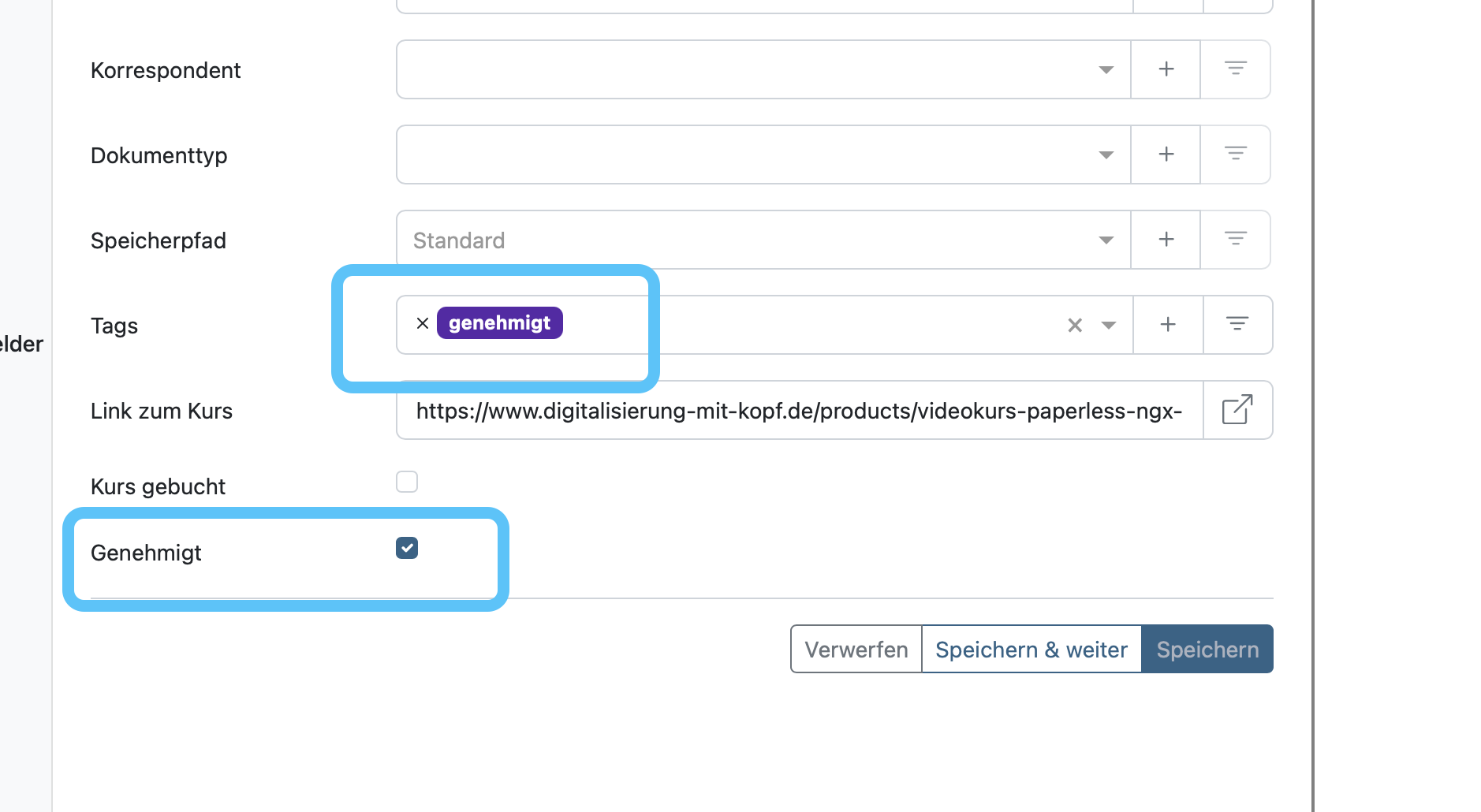
Bezüglich digitaler Signatur: Out of the Box nicht, aber man könnte eine Automatisierung schreiben, die sich z.B. Dokumente mit einem bestimmten benutzerdefinierten Feld (Signatur erforderlich=Wahr) nimmt und in das Signatur-Tool einfügt.
Ich selbst habe eine solche Automatisierung z.B. für den automatischen Upload zu lexware Office (meinem Buchhaltungstool) geschrieben, es würde für ein Signatur-Tool ähnlich funktionieren.
Werbung in eigener Sache
Solche Anbindungen sind übrigens der Grund, warum ich das Digitalisierungs-Coaching für Unternehmer ins Leben gerufen habe. Die erste Runde startet am 02. Dezember, es sind noch Plätze frei. Wenn du Interesse hast, melde dich gerne.
@WeisFred:
Wie Stefan schon sagt, gibt es Möglichkeiten, das abzubilden.
Achtung bei Digitalen Unterschriften: sollte ein Dokument durch ein Passwort oder eine Verschlüsselte Signatur versehen sein, verweigert Paperless grundsätzlich den Konsum. Eine simple eingebettete Signatur im PDF hingegen ist kein Problem. Allerdings kann Paperless diese nicht für dich einfügen - das muss schon an anderer Stelle geschehen - zB. durch eine Automatisierung wie sie Stefan oder ich gebaut haben. Ich kann auch rückwirkend jedes Attribut am Dokument in der Datenbank ändern. Dh.: nach Verarbeitung in einem Drittsystem spiele ich erforderliche Metadaten wieder zurück an das Original.
@Stefan Stefan,
Anbindungen sind ein Part, der Lösungen wie diese erst so richtig spannend machen. Zugegeben, gäbe es eine Reihe an Webhooks und event-getriebene Echtzeit Features, wäre ich vermutlich aufgeregt. Paperless sagt mir nicht, WANN Änderungen zB. an Tags getätigt wurden. Direkt nach Import lässt sich das durch einen sog. Post-Consumption Script abwickeln - alles danach ist derzeit nicht erfassbar. Die API ist aus meiner Sicht derzeit defekt und liefert auf Queries zu bestimmten Dokumenten IDs immer alle Dokumente. Lästig. Abgesehen davon lassen sich nicht alle Daten über die API ziehen. Drum habe ich eine eigene Schnittstelle gebaut und umgehe die API.
Ich ziehe mir Dokumente mitsamt Metadaten gezielt raus, sobald sie mit einem bestimmten Tag versehen wurden (Inbox ausgenommen), verarbeite sie extern in einer Middleware und schreibe ggf. benötigte Änderungen am Original in Paperless zurück in die Datenbank. So spiegelt sich die Nachbearbeitung an der Quelle wieder. Am Ende sind halt doch eine ganze Reihe an Tools im Spiel, die man im Alltag nutzt. Damit die Konsistenz der Daten über alle Systeme und Ebenen hinweg weitgehend gewahrt bleibt, spiele ich Metadaten in der Verarbeitungskette rückwärts.
Mein Use-Case ist: Dokumente mit dem Tag „Steuer“ werden über die Middleware an mein Steuerprogramm durchgereicht. Da die Steuersoftware selbst klassifiziert und Steuerkategorien zuordnet, kann ich das leider nicht vorab sinnvoller tun. So bleibt am Ende der Verarbeitungskette dennoch verringerter administrativer Aufwand.
Der zweite Use-Case ist, die Dokumente zu interpretieren, in mein eigenes lokales RAG zu stecken. So kann ich mit den Dokumenten „chatten“ und muss nicht in die Paperless UI und suchen gehen.
Aus der Architekten Brille auf die Verarbeitungskette geschaut, überlege ich mir, die Klassifikation & Interpretation der Dokumente VOR dem Konsum in Paperless durch einen Pre-consumption Script abzuwickeln, um die Erfassung in Paperless zu präzisieren…Fragen über Fragen ![]()
Ich hätte auf den Bau der Schnittstelle auch verzichten können - Der Weg über eine Automatisierung in Paperless, Ablage des Dokumentes in einem Ordner und einen Script zur Weitergabe an die Buchhaltung (so interpretiere ich deine Umsetzung), ist der weniger komplexe Weg hinaus.
Der Grund für meinen Ansatz, Rohdaten in einer Middleware zu verarbeiten, ist die enorme Flexibilität. Jetzt kann ich jedes Tool anbinden, das ich benötige - mit sehr überschaubarem Aufwand.
Dazu gibt es bereits Pull Requests, das Feature kommt wohl im nächsten Release ![]() Das wird unglaublich spannend.
Das wird unglaublich spannend.
Ich warte da eher auf das Beheben einiger recht nerviger Bugs. ![]()
Was nervt dich denn? Ich habe aktuell keinen Blocker in meinen Workflows, vielleicht übersehe ich aber was ![]()
Naja unschön ist es bei der Eingabe von Suchparametern erst mal ne fette rote Fehlerbox zu kriegen solange die Eingabe nicht vollständig ist.
Wenn der Import eines Dokumentes fehlschlägt und dieses eine ASN hat habe ich es noch nicht nicht hinbekommen, diese ASN zu benutzen. Nochmals scannen führt dann zu ASN bereits benutzt. Das führt zu hässliuchen Lücken.
Bei Duplikaten fehlt mir einfach eine Überschreibe-Möglichkeit. Wenn PLNGX mneint as wäre ein Duplikat, es aber keines ist, dann haääte ich gern ein Import-Anyhow. Fehlerfrei ist der Erkennungsalgorithmus ja nun nicht.
In gespeicherten Ansichten auf der Startseite kann man keine Dokumente selektieren.
Der Download von Dokumenten geschieht nicht in dem von mir verwendeten Speicherpfad, sondern irgendwas anderes. Ich kann zwar den Button oben rechts hernehmen und sage „speicher so wie es im Filesystem steht“, aber dann kriege ich den den Pfad noch mit und daher das ganze als ZIP Format.
Je nachdem wie man Dokumente importiert haben diese einen Eigentümer oder nicht. Ok, kann man mit einem Arbeitsablauf selber hinbiegen.
Wenn man mal was spezielles in der Ansicht eingestellt hat gibt es irgendwie keinen einfachen Weg zurück zu einer Art default. Definiert man sich selbst einen default, fragt er permanent nach, ob man denn speichern will, wenn man was anderes einstellt, weil man hat ja was verändert.
Will man ein tag löschen und deaktiviert es, poppt gleich ein Fenster mit allen anderne Tags auf. Ich will aber nur deaktivieren, nicht ein anderes Tag verpassen.
Im Papierkorb ist die Ansicht nur eine tabellarische Liste. Das macht es manchmal knifflig, herauszufinden, was dan nun für ein Dokument ist, welche sgelöscht wurde.
Das sind jetzt keine wirklichen Bugs, mich nervts aber schon. Und nein, ich hatte noch keine Lust, daraus issues oder FRs zu machen. Und weil ich es noch nicht gemacht habe, kann es so schlimm ja nicht sein ![]() Jammern auf hohem Niveau also.
Jammern auf hohem Niveau also.
PS: Naja nicht ganz, den „ich weiss besser dass das kein Duplikat ist“ Button habe ich als FR eingestellt, aber nur mit wenig Resonanz.
Stimmt, das meiste davon kenne ich. Hat mich bisher aber nicht genug gestört, um ein Ticket zu erstellen ![]()
Das Thema mit den Duplikaten ist mir so noch nicht aufgefallen, bin aber bei dir, dass das nicht gut ist. Ich würde fast sogar so weit gehen, die Duplikaterkennung zu deaktivieren, wenn’s denn ginge. Schön wäre etwas in Richtung:
- Dokument wird dennoch importiert
- „Duplikat“ wird im Urprungsdokument verlinkt
- Zentrale Duplikats-Ansicht, die man manuell administrieren kann.
There was an important job to be done and Everybody was sure that Somebody would do it. Anybody could have done it, but Nobody did it. Somebody got angry about that, because it was Everybody’s job. Everybody thought Anybody could do it, but Nobody realized that Everybody wouldn’t do it. It ended up that Everybody blamed Somebody when Nobody did what Anybody could have done.
2 „Gefällt mir“
Eieiei…hätte ich Eumel da mal früher rein geschaut. Nuja, so habe ich was gelernt und meine Python & SQL Künste aufpoliert. ![]() Auch nicht schlecht. Die Frage ist am Ende, was die Webhooks alles liefern - also welche Prozess- File- & DB Event Attribute mitgeliefert werden. Deshalb setzte ich mich ganz frech auf die DB - denn da schreibe ich alles an der Quelle mit, egal, was implementiert ist.
Auch nicht schlecht. Die Frage ist am Ende, was die Webhooks alles liefern - also welche Prozess- File- & DB Event Attribute mitgeliefert werden. Deshalb setzte ich mich ganz frech auf die DB - denn da schreibe ich alles an der Quelle mit, egal, was implementiert ist.
danke für den Hinweis!
Hmja, I feel your pain. Der Erkennungsprozess & Algorithmus ist…not super. Nur ganz gut ![]()
So sehr ich Paperless schätze, so sehr denke ich über Alternativen bei der Dokumentenerkennung nach…die Workflows in Paperless sind…puh starr, redundant, unflexibel - kurzum: stark limitiert. Klar ist das jammern auf hohem Niveau - aber Paperless zieht ja nun keine Amateure sondern Poweruser an, die konkrete Probleme bewältigen möchten. Da darf man den Maßstab schon etwas höher ansetzen. Und selbst wenn es einen Weg gibt, Dinge umzusetzen, so sind sie manchmal holprig und schaffen mehr Arbeit & @huebi Probleme als man damit löst. Grade, wenn es um die Flexibilität von Kategorisierung geht oder anknüpfende Workflows. Man sollte Prozesse und Workflows zwar immer so simpel wie möglich halten, um nicht selbst daran zu scheitern - aber wir alle kennen es: manchmal wird man zu irrem Bürokratieirrsinn gezwungen, der absurde Stunts im Hintergrund abverlangt. Edge-Case, ja. Aber manchmal ist Edge-Case gelöst im Alltag bessere Laune ![]()
Deshalb schubse ich die Dokumente vermutlich künftig vor Konsum in Paperless durch mein lokales RAG, um sicherzustellen, dass Paperless nur qualitätsgesichertes Material erhält und über den Dokumententitel befüttert wird. Gleichzeitig möchte ich über den Pre-consumption Script bereits erweiterte Metadaten anliefern. Keine Ahnung, ob das geht - muss mir die Doku dazu mal genauer ansehen. Denn Informationen nur im Titel zu hinterlegen…puhhh naja.